무작위 수를 생성할 필요가 종종 있다.
무작위로 생성된 수를 난수(random number)라 부르며,
난수 생성을 위해 랜덤(random) 모듈을 사용할 수 있다.
import random
random 함수¶0과 1 사이의 실수를 무작위로, 하지만 균등하게(uniformly) 선택한다. 여기서 균등성은 한 영역에 치우치지 전 영역에서 골고루 선택함을 의미한다.
[random.random() for _ in range(10)]
[0.7764831379039491, 0.7721862172016177, 0.0867863503071542, 0.4410254619362748, 0.4250708399315549, 0.8228697504316219, 0.7051326260113755, 0.2618624536553694, 0.11785573022215512, 0.8454633651490482]
주의: 난수 생성이 엄밀히 말하면 완전히 무작위는 아니다.
모든 컴퓨터 안에 난수표가 있어서 random 같은 함수를 실행할 때마다
난수표에서 차례대로 읽어서 보여주는 것에 불과하다.
하지만 우리 인간에게는 무작위적으로 보이며, 실제로 매우 유용하게 활용된다.
seed) 함수¶코드를 실행할 때 마다 동일한 난수를 얻으려면,
즉, 동일한 환경에서 데이터 분석 실험을 반복하려면
seed 함수를 먼저 실행해야 한다.
간단한게 설명하면, seed 함수에 입력된 정수 인자가
난수를 생성하는 기준을 제시한다.
따라서 어떤 환경에서도 seed 함수의 입력값이 동일하면
동일한 난수가 생성된다.
random.seed(10) # 시드를 10으로 지정
print(random.random())
random.seed(10)
print(random.random())
0.5714025946899135 0.5714025946899135
시드를 지정하지 않으면 random 함수가 매번 다른 값을 생성한다.
print(random.random())
0.4288890546751146
print(random.random())
0.5780913011344704
print(random.random())
0.20609823213950174
random.randrange(10)
7
실행할 때마다 다른 값을 반환한다.
random.randrange(10)
4
그리고, 예를 들어, 3과 7 사이의 정수 중에서 임의로 하나를 선택하려면 다음과 같이 실행한다.
random.randrange(3, 7)
4
역시 실행할 때마다 다른 값을 반환한다.
random.randrange(3, 7)
3
하지만 seed 를 지정하면 매번 동일한 값을 반환한다.
random.seed(0)
random.randrange(3,7)
6
random.seed(0)
random.randrange(3,7)
6
random.seed(0)
random.randrange(3,7)
6
shuffle 함수¶리스트의 항목들을 무작위로 섞고자 할 때 사용한다.
up_to_ten = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
random.shuffle(up_to_ten)
print(up_to_ten)
[9, 10, 2, 3, 6, 4, 8, 5, 1, 7]
역시 실행할 때마다 다르게 섞는다.
up_to_ten = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
random.shuffle(up_to_ten)
print(up_to_ten)
[6, 5, 9, 7, 1, 2, 8, 3, 4, 10]
하지만 시드를 지정하면 항상 동일한 결과를 보인다.
random.seed(50)
up_to_ten = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
random.shuffle(up_to_ten)
print(up_to_ten)
[9, 7, 1, 3, 4, 2, 10, 6, 5, 8]
random.seed(50)
up_to_ten = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
random.shuffle(up_to_ten)
print(up_to_ten)
[9, 7, 1, 3, 4, 2, 10, 6, 5, 8]
choice 함수¶리스트에서 임의로 하나의 항목을 선택할 때 사용한다.
random.choice(["Alice", "Bob", "Charlie"])
'Alice'
실행할 때마다 값이 달라질 수 있다. 그리고 중복 선택이 가능하다.
random.choice(["Alice", "Bob", "Charlie"])
'Charlie'
random.choice(["Alice", "Bob", "Charlie"])
'Charlie'
시드를 지정하면 동일한 결과를 얻는다.
random.seed(100)
random.choice(["Alice", "Bob", "Charlie"])
'Alice'
random.seed(100)
random.choice(["Alice", "Bob", "Charlie"])
'Alice'
random.seed(100)
random.choice(["Alice", "Bob", "Charlie"])
'Alice'
sample 함수¶리스트에서 지정한 개수만큼의 항목을 무작위로 선택해서 새로운 리스트를 생성할 수도 있다. 중복선택이 없다. 따라서 일종의 로또 뽑기와 비슷하게 작동한다.
lottery_numbers = range(60)
random.sample(lottery_numbers, 6)
[29, 59, 49, 11, 45, 25]
실행할 때 마다 다르게 선택한다.
lottery_numbers = range(60)
random.sample(lottery_numbers, 6)
[46, 22, 27, 32, 51, 7]
시드를 지정하면 변하지 않는다.
random.seed(0)
lottery_numbers = range(60)
random.sample(lottery_numbers, 6)
[54, 24, 48, 56, 26, 2]
random.seed(0)
lottery_numbers = range(60)
random.sample(lottery_numbers, 6)
[54, 24, 48, 56, 26, 2]
choice와 range의 합작¶두 함수를 합작하면 sample 함수와 유사하게 작동하는 코드를 구현할 수 있다.
차이점은 중복 선택이 가능하다라는 점이다.
예를 들어, 0부터 99 사이의 정수 중에서 중복을 허락하면서 무작위로 10개의 정수를 선택하고자 할 때 다음과 같이 실행한다.
four_with_replacement = [random.choice(range(100)) for _ in range(10)]
print(four_with_replacement)
[33, 65, 62, 51, 38, 61, 45, 74, 27, 64]
실행할 때마다 결과가 다르다.
four_with_replacement = [random.choice(range(100)) for _ in range(10)]
print(four_with_replacement)
[17, 36, 17, 96, 12, 79, 32, 68, 90, 77]
시드를 지정하면 항상 동일하다.
random.seed(5)
four_with_replacement = [random.choice(range(100)) for _ in range(10)]
print(four_with_replacement)
[79, 32, 94, 45, 88, 94, 83, 67, 3, 59]
random.seed(5)
four_with_replacement = [random.choice(range(100)) for _ in range(10)]
print(four_with_replacement)
[79, 32, 94, 45, 88, 94, 83, 67, 3, 59]
정규표현식은 문장을 탐색할 때 매우 유용하며, 탐색 대상의 패턴(pattern, 형태)을 지정한다. 하지만 사용법이 꽤 복잡하기도 해서 한 권의 책으로 나올 정도이다. 따라서 앞으로 정규표현식 예제가 나올 때마다 필요한 정도만 자세히 다룰 것이며, 여기서는 간단하 예제를 통해 정규표현식의 역할을 살펴본다.
먼저, 정규표현식 탐색에 필요한 도구를 모아놓은 re 모듈을 불러와야 한다.
import re
match 함수¶사용법
re.match(패턴, 문자열)
의미: 문자열이 정규표현식이 지정한 문자열로 시작하는지 여부를 판단
예를 들어, 문자열이 ca로 시작하는지 여부를 알고자 하면 다음처럼 실행한다.
패턴 매칭이 성립하면 Match 객체가 리턴되며 매칭이 성공했음을 알려준다.
re.match("ca", "cat")
<_sre.SRE_Match object; span=(0, 2), match='ca'>
위 결과는 cat 문자열의 0번부터 2번 이전 인덱스까지 지정된 패턴으로 시작된다는 정보를 보여준다.
반면에 패턴 매칭이 성공하지 못하면 None을 리턴한다.
print(re.match("ca", "kat"))
None
True 또는 False¶패턴 매칭이 성공하면 True, 실패하면 False로 간주된다.
if re.match("ca", "cat"):
print("참")
else:
print("거짓")
참
if re.match("ca", "kat"):
print("참")
else:
print("거짓")
거짓
search 함수¶사용법
re.search(패턴, 문자열)
의미: 문자열이 정규표현식이 지정한 문자열을 부분문자열로 포함하는지 여부를 판단
match의 경우와 동일.re.search("at", "cat")
<_sre.SRE_Match object; span=(1, 3), match='at'>
re.search("at", "cot")
[]) 패턴 규칙¶지금 까지는 특정 문자열의 포함여부만을 살펴보았다. 하지만 특정 문자열 뿐만 아니라 특정 형태를 띄는 문자열을 탐색할 수도 있다.
예를 들어, 0부터 9까지의 숫자 중 하나로 시작 또는 포함하는지 여부를 물을 수 있다.
이를 위해 사용할 패턴은 [0-9] 이다.
[])는 안에 포함된 문자들 중의 아무 문자 하나를 의미한다.0-9: 0부터 9까지의 정수를 가리킨다.a-f: 알파벳 a부터 f까지, 즉, a, b, c, d, e, f를 가리킨다.re.match("[0-9]", "cot")
re.match("[0-9]", "3cot")
<_sre.SRE_Match object; span=(0, 1), match='3'>
re.search("[0-9]", "cot35")
<_sre.SRE_Match object; span=(3, 4), match='3'>
re.match("[a-f]", "pat")
re.search("[a-f]", "pat")
<_sre.SRE_Match object; span=(1, 2), match='a'>
split 함수¶사용법
re.split(패턴, 문자열)
의미: 지정된 패턴으로 문자열을 쪼갠다.
예를 들어, a 또는 b로 문자열을 쪼개고자 할 때 다음처럼 실행한다.
re.split("[ab]", "caribbean")
['c', 'ri', '', 'e', 'n']
즉, "caribbean"이 "c"-a-"ri"-b-""-b-"e"-a-"n"로 쪼개졌다.
sub 함수¶사용법
re.sub(패턴, 대입문자열, 문자열)
의미: 지정된 패턴으로 탐색된 문자열 대신에 지정된 대입문자열을 삽입한다.
예를 들어, 0부터 9까지의 숫자 대신에 대시(-)를 사용하고 싶으면 아래와 같이 실행한다.
re.sub("[0-9]", "-", "R2D2")
'R-D-'
정규표현식에 대한 정보와 활용법은 매우 중요하며 아래 사이트를 이용하여 공부할 것을 추천한다.
zip) 함수와 인자 해체(argument unpacking)¶리스트, 튜플 등 이터러블(iterable) 자료형 두 개 이상을 짝짓기를 통해 하나로 묶어야 할 때가 있다. 예를 들어, 두 개의 리스트의 항목을 순서대로 쌍으로 묶어 새로운 리스트를 생성할 수 있다.
list_abc = ['a', 'b', 'c']
list_abc_indices = [0, 1, 2]
list_pairs = zip(list_abc, list_abc_indices)
tuple_a = ('a', 0)
tuple_b = ('b', 1)
tuple_c = ('c', 2)
tuple_pairs = zip(tuple_a, tuple_b, tuple_c)
zip은 소극적인 함수이다. 즉, 필요한 만큼만 계산하고 결과를 생성한다.
print(list_pairs)
<zip object at 0x7f95d8234b48>
print(tuple_pairs)
<zip object at 0x7f95d8234cc8>
따라서 결과물을 확인하려면 아래와 같이 리스트 조건제시법 등을 활용해야 한다.
[pair for pair in list_pairs]
[('a', 0), ('b', 1), ('c', 2)]
[pair for pair in tuple_pairs]
[('a', 'b', 'c'), (0, 1, 2)]
서로 길이가 다른 리스트를 대상으로 zip 함수를 사용하면 가장 짧은 리스트의 길이만큼만 짝짓기를 실행한다.
list_abcd = ['a', 'b', 'c', 'd']
abc_indices = [0, 1, 2]
list_count = ['first', 'second']
list_pairs_d = zip(list_abcd, abc_indices, list_count)
[pair for pair in list_pairs_d]
[('a', 0, 'first'), ('b', 1, 'second')]
숫자 세 개의 평균을 계산해주는 함수를 아래와 같이 정의하자.
def mean3(a, b, c): return (a+b+c)/3
이제 mean3 함수를 호출하려면 반드시 인자 두 개를 입력해야 한다.
mean3(1, 2, 3)
2.0
그런데 길이가 3인 리스트나 튜플을 인자로 사용할 수 있다.
대신 인자를 해체해야 하며 이를 위해 별표(*)를 사용한다.
mean3(*[1, 2, 3])
2.0
mean3(*(1, 3, 5))
3.0
주의: 별표를 사용하지 않으면 오류가 발생한다.
mean3([1, 2, 3])
--------------------------------------------------------------------------- TypeError Traceback (most recent call last) <ipython-input-57-717d17375452> in <module> ----> 1 mean3([1, 2, 3]) TypeError: mean3() missing 2 required positional arguments: 'b' and 'c'
mean3((1, 2, 3))
--------------------------------------------------------------------------- TypeError Traceback (most recent call last) <ipython-input-58-aea8908655ed> in <module> ----> 1 mean3((1, 2, 3)) TypeError: mean3() missing 2 required positional arguments: 'b' and 'c'
인자 해체 기술을 응용하여 짝짓기가 된 쌍들의 리스트를 해체하여 두 개의 리스트로 되돌릴 수 있다. 다만 방식이 꽤나 생소하게 보일 수 있다.
앞서 zip으로 생성한 list_pairs를 해체해서 기존 두 개의 리스트를 복구해보자.
list_abc = ['a', 'b', 'c']
list_abc_indices = [0, 1, 2]
list_pairs = zip(list_abc, list_abc_indices)
for i in list_pairs:
print(i)
('a', 0)
('b', 1)
('c', 2)
list_pairs를 아래 형태의 리스트를 소극적(lazy)으로 담고 있다.
pairs = [('a', 0), ('b', 1), ('c', 2)]
이제 pairs를 해체하면서 zip 함수의 인자로 입력하면
아래 세 개의 인자를 zip 함수의 인자로 입력하는 것과 동일하다.
('a', 0), ('b', 1), ('c', 2)
따라서 zip(*pairs)는 아래 모양의 리스트를 품은 값이 된다.
[('a', 'b', 'c'), (0, 1, 2)]
아래 코드를 실행하면 동일한 결과를 확인할 수 있다.
letters, numbers = zip(*pairs)
print(f"letters = {letters}", f"numbers = {numbers}", sep='\n')
letters = ('a', 'b', 'c')
numbers = (0, 1, 2)
함수를 선언할 때 아래 형태처럼 인자의 개수를 지정하는 것이 일반적이다.
def 함수이름(매개변수1, ..., 매개변수n):
함수본체
하지만 원하는 대로 많은 인자를 받을 수 있도록 해야 하는 경우가 발생한다.
이를 위해 파이썬은 관습적으로 args와 kwargs라 불리며 특별한 역할을 수행하는 매개변수를 사용한다.
꽤 유용한 기법이지만 여기서는 고계함수를 선언하면서 반드시 필요한 경우에 한정해서 사용할 것이다.
파이썬에서 함수는 제1종 객체이며, 따라서 다른 함수의 인자로 사용될 수 있다. 이렇게 함수를 인자로 입력받을 수 있는 함수를 고계함수(higher-order function)라 부른다.
예를 들어, 함수 f를 입력 받으면 f의 반환값의 두 배를 반환하는 새로운 함수를 반환하는
doubler 함수를 정의해 보자.
def doubler(f):
# 함수 f가 입력되었다고 가정하자.
# 이제 임의의 x 에 대해 2*f(x)를 반환하는 함수 g를 선언하자.
def g(x):
return 2 * f(x)
# 이제 함수 g를 doubler(f)의 반환값으로 지정한다.
return g
doubler 함수의 인자로 다음 함수 f1을 사용해보자.
def f1(x):
return x + 1
g = doubler(f1)
g(x)가 f(x)의 두 배임을 확인할 수 있다.
g(3) == 2 * f1(3)
True
g(-1) == 2 * f1(-1)
True
하지만 두 개의 인자를 받는 다음 함수 f2에 대해서는 doubler를 실행시킬 수 없다.
def f2(x, y):
return x + y
g = doubler(f2)
try:
g(1, 2)
except TypeError:
print("함수 g는 하나의 인자만을 허용한다.")
함수 g는 하나의 인자만을 허용한다.
임의로 많은 인자를 받는 함수를 선언하는 일반적인 형식은
아래 magic 함수의 경우와 비슷하다.
def magic(*args, **kwargs):
print("일반 인자들:", args)
print("옵션 인자들:", kwargs)
주의:
일반 인자들을 위한 매개변수 args에는 한 개의 별표(*)를 붙힌다
*agrs 는 앞서 설명한 리스트 또는 튜플 인자 해체(unpacking) 기법과 동일하다.옵션 인자들을 위한 옵션 매개변수 kwargs에는 두 개의 별표(**)를 붙힌다.
**kwagrs 는 사전 자료형의 인자 해체(unpacking)를 의미한다.magic(1, 2, key1="단어", key2="단어2", key3="단어3")
일반 인자들: (1, 2)
옵션 인자들: {'key1': '단어', 'key2': '단어2', 'key3': '단어3'}
주의:
def f3(x, y, z):
return x + y + z
이제 길이가 2인 리스트 한 개와 한 개의 항목을 가진 사전 자료형을 해체 기법을 이용하여 인자로 사용해보자.
x_y_list = [1, 2]
z_dict = {"z": 3}
f3(*x_y_list, **z_dict) == f3(1, 2, 3)
True
앞서 살펴 본 doubler 함수를 일반화 하여
임의로 많은 인자를 받은 함수를 인자로 사용할 수 있도록
args와 kwargs 기법을 이용할 수 있다.
def doubler_correct(f):
"""f는 임의의 함수를 받아들인다."""
# 함수 f가 인자로 들어오면 동일한 인자를 사용하는 함수 g를 선언한다.
# 함수 g는 인자를 받으면 그대로 모두 함수 f에 전달한다.
# 그리고 함수 f의 반환값을 두 배하여 반환한다.
def g(*args, **kwargs):
return 2 * f(*args, **kwargs)
return g
이제 f2에 대해서도 2배 함수가 작동한다.
g2 = doubler_correct(f2)
g2(1, 2) == 2 * f2(1, 2)
True
g3 = doubler_correct(f3)
g3(1, 2, 3) == 2 * f3(1, 2, 3)
True
파이썬은 동적 타이핑(dynamic typing)을 지원하는 언어이다. 즉, 함수나 변수를 선언할 때 변수들의 자료형을 명시적으로 제한하지 않는다. 동적 타이핑 언어의 경우 프로그램 실행 과정에서 문제가 발생하지 않도록 프로그램을 작성해야 한다.
예를 들어 아래 add 함수를 보자.
def add(a, b):
return a + b
add 함수의 인자로 정수, 실수, 리스트, 문자열이 사용될 수 있다.
assert add(10, 5) == 15, "정수들에 대해 + 사용 가능"
assert add([1, 2], [3]) == [1, 2, 3], "리스트들에 대해 + 사용 가능"
assert add("저 ", "잠깐만요!") == "저 잠깐만요!", "문자열들에 대해 + 사용 가능"
하지만 두 인자가 동일한 자료형을 가져야 한다. 예를 들어, 숫자와 문자열의 덧셈은 작동하지 않는다. 이유는 숫자와 문자열의 덧셈이 정의되어 있지 않기 때문이다.
try:
add(10, "five")
except TypeError:
print("정수와 문자열은 서로 더할 수 없어요!")
정수와 문자열은 서로 더할 수 없어요!
C, Java 등 많은 프로그래밍 언어는 동적 타이핑 대신에 정적 타이핑(static typing)을 지원한다. 즉, 함수나 변수를 선언할 때 사용되는 변수들의 자료형과 인자 및 반환값의 자료형을 애초부터 명시해야 하며 지정된 자료형이 사용되지 않을 경우 오류를 발생시킨다.
파이썬은 3.6 버전부터 정적 타이핑 형식을 지원한다. 다만 C, Java의 자료형과 관련된 엄격함은 전혀 존재하지 않으며, 그냥 정적 타이핑의 형식만 빌려왔다.
즉, 자료형 명시(type annotations)를 지원할 뿐이며,
실제로는 동적 타이핑 방식을 사용한다.
예를 들어, add 함수를 아래와 같이 선언할 수 있다.
def add(a: int, b: int) -> int:
return a + b
하지만 여전히 문자열이나 리스트를 인자로 사용할 수 있다.
print(add(10, 5))
print(add([1, 2], [3]))
print(add("저 ", "잠깐만요!"))
15 [1, 2, 3] 저 잠깐만요!
비록 형식적더라도 자료형 명시하기가 주는 장점이 크게 네 가지이다.
첫째, 문서화 및 프로그래밍 교육에 유용하다.
예를 위해, 먼저 벡터 자료형을 실수들의 리스트들의 집합으로 정의하자.
typing) 모듈에 포함되어 있다.List[float]로 정의된다.from typing import List
Vector = List[float]
이제 아래 두 개의 정의를 비교하면 둘째 정의가 보다 많은 정보를 우리에게 제공함을 알 수 있다.
정의 1: 전통적 방식
def dot_product(x, y): ...
정의 2: 자료형 명시
def dot_product(x: Vector, y: Vector) -> float: ...
둘째, mypy 와 같은 제3자가 개발한 툴을 이용하여 파이썬 코드를 실행하기 전에
작성된 코드에 사용된 함수와 변수들이 적절한 자료형을 사용했는지 여부를
검사해주는 툴을 활용할 수 있다.
하지만 여기서는 사용하지 않을 것이며, 대신에 관심이 있다면 mypy 공식 문서를 참조하기를 추천한다.
셋째, 자료형을 명시적으로 보여줌으로써 보다 정제된 함수와 인터페이스를 디자인할 수 있다.
예를 들어, 아래 secretly_ugly_function인 경우 value와 operation 매개변수에
사용할 인자들의 자료형을 함수의 본체를 들여다보기 전까지는 전혀 알 수 없다.
def secretly_ugly_function(value, operation): ...
아래 ugly_function 또한 여전히 부자연스럽다.
from typing import Union
def ugly_function(value: int, operation: Union[str, int, float, bool]) -> int:
...
왜냐하면 둘째 매개변수 operation에 할당될 수 있는 함수는 인자로
str, int, float, bool 중의 하나의 자료형을 받아들일 수 있기 때문이다.
그래도 이렇게 자료형을 명시하면
사용자들이 프로그램을 보다 쉽게 이해할 수 있도록 도와준다.
주의: Union은 합집합을 나타내는 기호이다.
넷째, 소스코드 에디터의 자동완성 기능을 보다 적절하게 지원하게 만들어 주며, 따라서 보다 빠르게 오류 없는 프로그램을 작성할 수 있도록 도와준다.
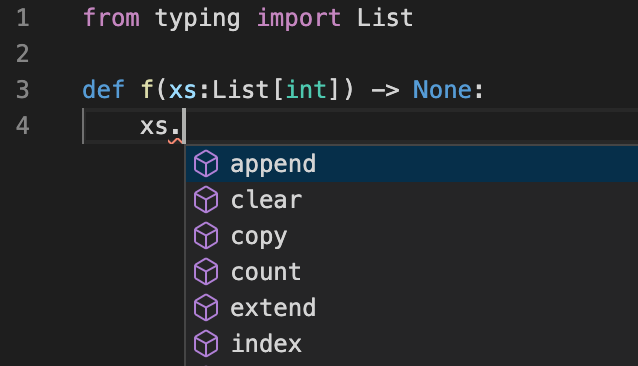
예를 들어, VSCode 에디터에서 아래 코드를 작성하다 보면
매개변수 xs가 정수들의 리스트를 입력받을 것으로 기대하며,
리스트의 메소드의 목록을 보여주며 코드 작성을 도와주려 시도한다.
(구글 코랩은 아직 지원하지 않음.)
int, bool, float, str 등은 그대로 사용a:int, b:bool, c:float, s:str 등등list 라고 하는 것은 별 도움 않됨. def total(xs: list) -> float:
return sum(xs)
from typing import List # 대문자 L 사용에 주의할 것
def total(xs: List[float]) -> float:
return sum(xs)
변수의 자료형도 명시할 수 있다.
x: int = 5
경우에 따라 변수의 자료형이 명확하지 않아서 자료형을 명시하면 많은 도움을 받을 수 있다. 예를 들어, 아래 두 변수는 어떤 종류의 리스트인지 명확하지 않다.
values = []
대신에 아래의 경우는 아주 명확하다. 즉, 빈 리스트이면서 정수들의 리스트 중에 하나임을 명확히 보여준다.
values : List[int]= []
Optional 자료형¶아래의 경우는 애매함이 더욱 심하다.
best_so_far = None
None은 '아무 값도 아니다'를 가리키는 '값'이다.
하지만 변수는 어떤 값을 가리키기 위해 존재하며, 새로운 값을 언제라도 가리킬 수 있다.
따라서 None이 언제라도 다른 값으로 대체될 수 있으며,
대체될 값의 자료형을 암시해줄 필요가 있다.
이를 위해 옵셔널(Optional) 자료형을 List 자료형과 유사한 방법으로 활용할 수 있다.
from typing import Optional
best_so_far: Optional[float] = None
위와 같이 하면 best_so_far 변수에는 실수(float) 자료형이 할당될 것으로
기대함을 바로 알 수 있다.
즉, float 자료형 또는 None 값을 위해 best_so_far 변수를 사용할 것이라고
명시하는 것이다.
typing 모듈¶타이핑(typing)은 List, Optional 이외에도 다른 많은 자료형을 포함하고 있다.
그중에 일부만 다룰 예정이다.
from typing import Dict, Iterable, Tuple
counts 변수는 문자열을 키(key)로, 정수를 키값으로 사용하는 사전 자료형을 담고 있다.
counts: Dict[str, int] = {'data': 1, 'science': 2}
evens 변수는 0부터 9사이의 짝수를 소극적(lazy) 리스트로 담고 있다.
evens: Iterable[int] = (x for x in range(10) if x % 2 == 0)
triple 변수는 정수, 실수, 정수 세 개의 값을 갖는 튜플이다.
triple: Tuple[int, float, int] = (10, 2.3, 5)
Callable 함수의 자료형¶파이썬에서 함수는 제1종 객체이다.
즉, 함수의 인자로 함수를 입력할 수 있다.
따라서 함수를 가리키는 매개변수의 자료형도 명시할 수 있어야 한다.
이를 위해 Callable(호출가능한) 자료형을 활용한다.
from typing import Callable
def twice(repeater: Callable[[str, int], str], s: str) -> str:
return repeater(s, 2)
twice 함수는 첫째 인자로 Callable[[str, int], str] 자료형의 함수를 인자로 받는다.Callable[[str, int], str] 는 아래 특징을 갖는 함수들의 자료형을 가리킨다.str)int)str)예를 들어, 아래 함수 comma_repeater를 twice 함수의 인자로 입력해보자.
def comma_repeater(s: str, n: int) -> str:
n_copies = [s for _ in range(n)]
return ', '.join(n_copies)
comma_repeater("type hints", 2)
'type hints, type hints'
twice(comma_repeater, "type hints")는
comma_repeater("type hints", 2)의 반환값을 반환한다.
twice(comma_repeater, "type hints") == comma_repeater("type hints", 2)
True
자료형을 명시하기 위해 사용된 자료형들 자체도 파이썬 객체이다. 즉, 변수에 할당할 수 있는 값으로 사용될 수 있다.
예를 들어, 복잡한 자료형을 단순한 이름으로 지정하여 다시 자료형 명시를 위해 사용할 수 있다.
Number = int
Numbers = List[Number]
def total(xs: Numbers) -> Number:
return sum(xs)