|
|
| <출처 > 위키:미분 | <출처 > pvigier: gradient-descent |
이전에 정의한 함수를 사용하기 위한 준비가 필요하며,
이전에 사용한 모든 파이썬 코드가 ../scratch/ 디렉토리에 저장되어 있다고 가정한다.
여기서는 선형대수 모듈에 포함되어 있는 Vector 자료형과 dot (벡터곱)함수를 불러온다.
Vector = List[float]dot(v:Vector, w:Vector) -> floatimport os
import sys
sys.path.insert(0, os.path.abspath('..'))
# 선형대수 모듈로부터 Vector 자료형과 dot 함수 불러오기
from scratch.linear_algebra import Vector, dot
주어진 데이터셋을 가장 잘 반영하는 최적의 수학적 모델을 찾으려 할 때 가장 기본적으로 사용되는 기법이 경사하강법(gradient descent)이다. 최적의 모델에 대한 기준은 학습법에 따라 다르지만, 보통 학습된 모델의 오류를 최소화하도록 유도하는 기준을 사용한다.
여기서는 선형회귀 모델을 학습하는 데에 기본적으로 사용되는 평균 제곱 오차(mean squared error, MSE)를 최소화하기 위해 경사하강법을 적용하는 과정을 살펴본다.
함수 $f:\textbf{R}^n \to \textbf{R}$의 최댓값(최솟값)을 구하고자 한다. 예를 들어, 길이가 $n$인 실수 벡터를 입력받아 항목들의 제곱의 합을 계산하는 함수가 다음과 같다고 하자.
$$ f(\mathbf x) = f(x_1, ..., x_n) = \sum_{k=1}^{n} x_k^2 = x_1^2 + \cdots x_n^2 $$아래 코드에서 정의된 sum_of_squares()가 위 함수를 파이썬으로 구현한다.
def sum_of_squares(v: Vector) -> float:
"""
v 벡터에 포함된 원소들의 제곱의 합 계산
"""
return dot(v, v)
이제 sum_of_squares(v)가 최대 또는 최소가 되는 벡터 v를 찾고자 한다.
그런데 특정 함수의 최댓값(최솟값)이 존재한다는 것이 알려졌다 하더라도 실제로 최댓값(최솟값) 지점을 확인하는 일은 일반적으로 매우 어렵고, 경우에 따라 불가능하다. 따라서 보통 해당 함수의 그래프 위에 존재하는 임의의 점에서 시작한 후 그레이디언트를 방향(반대 방향)으로 조금씩 이동하면서 최댓값(최솟값) 지점을 찾아가는 경사하강법(gradient descent)을 이용한다.
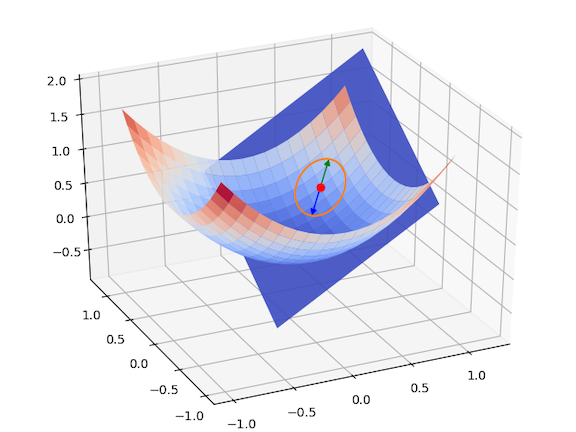
함수 $f:\textbf{R}^n \to \textbf{R}$가 vector $\textbf{x}\in \textbf{R}$에서 미분 가능할 때 그레이디언트는 다음처럼 편미분으로 이루어진 벡터로 정의된다.
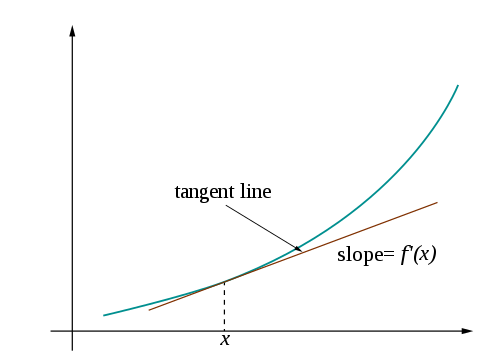
$$ \nabla f(\textbf{x}) = \begin{bmatrix} \frac{\partial}{\partial x_1} f(\textbf{x}) \\ \vdots \\ \frac{\partial}{\partial x_n} f(\textbf{x}) \end{bmatrix} $$아래에서 왼편 그림은 $n=1$인 경우 2차원 상에서, 오른편 그림은 $n=2$인 경우에 3차원 상에서 그려지는 함수의 그래프와 특정 지점에서의 그레이디언트를 보여주고 있다.
|
|
|
| <출처 > 위키:미분 | <출처 > pvigier: gradient-descent |
경사하강법은 다음 과정을 반복하여 최댓값(최솟값) 지점을 찾아가는 것을 의미한다.
아래 그림은 2차원 함수의 최솟값을 경사하강법으로 찾아가는 과정을 보여준다. 최솟값은 해당 지점에서 구한 그레이디언트의 반대방향으로 조금씩 이동하는 방식으로 이루어진다.
최솟값 지점에 가까워질 수록 그레이디언트는 점점 0벡터에 가까워진다. 따라서 그레이디언트가 충분히 작아지면 최솟값 지점에 매우 가깞다고 판단하여 그 위치에서 최솟값의 근사치를 구하여 활용할 수 있다.
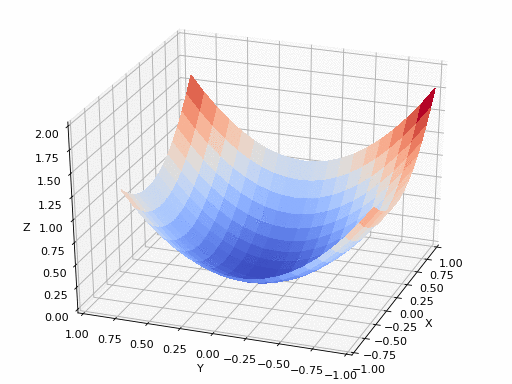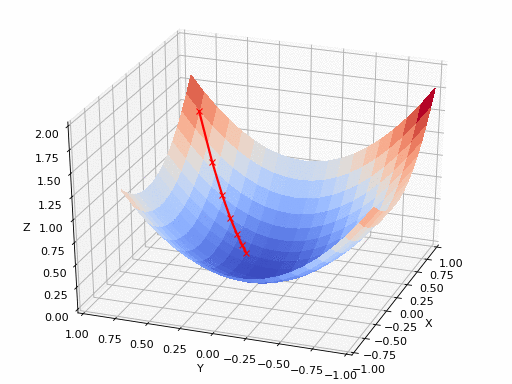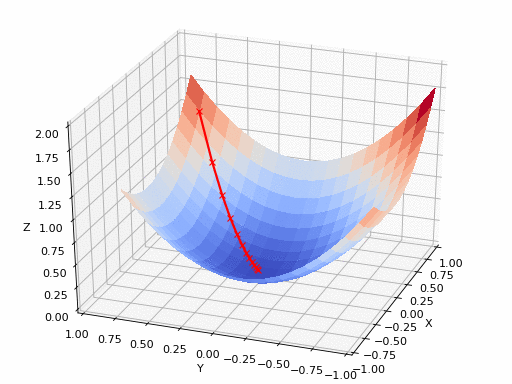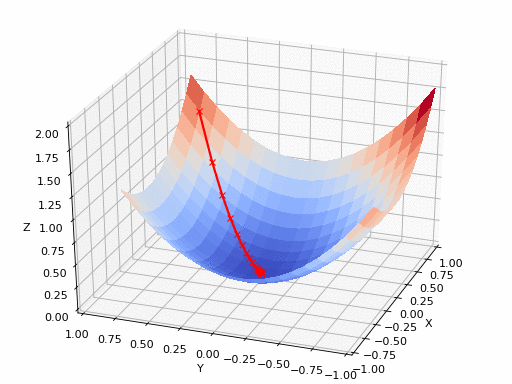 <출처 > <a href=""https://github.com/pvigier/gradient-descent>pvigier: gradient-descent </a>
<출처 > <a href=""https://github.com/pvigier/gradient-descent>pvigier: gradient-descent </a>
경사하강법은 지역 최솟값(local minimum)이 없고 전역 최솟값(global mininum)이 존재할 경우 유용하게 활용된다. 반면에 지역 최솟값이 존재할 경우 제대로 작동하지 않을 수 있기 때문에 많은 주의를 요한다. 아래 그림은 출발점과 이동 방향에 따라 도착 지점이 전역 또는 지역 최솟점이 될 수 있음을 잘 보여준다.
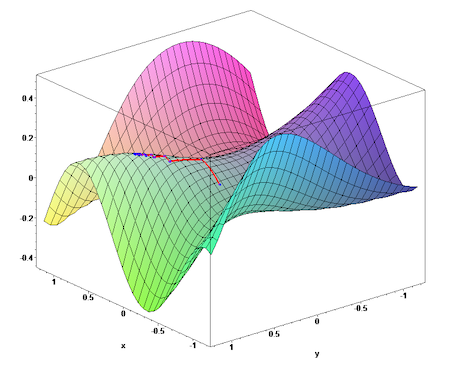 <출처 > 위키:미분
<출처 > 위키:미분
단변수 함수와 다변수 함수의 경우 그레이디언트 계산이 조금 다르다.
$f$가 단변수 함수(1차원 함수)일 때, 점 $x$에서의 그레이디언트는 다음과 같이 구한다.
$$ f'(x) = \lim_h \frac{f(x+h) - f(x)}{h} $$즉, $f'(x)$ 는 $x$가 아주 조금 변할 때 $f(x)$가 변하는 정도, 즉 함수 $f$의 $x$에서의 미분값이 된다. 이때 함수 $f'$ 을 함수 $f$의 도함수라 부른다.
예를 들어, 제곱 함수 $f(x) = x^2$에 해당하는 square()가 아래와 같이 주어졌다고 하자.
def square(x: float) -> float:
return x * x
그러면 square()의 도함수 $f'(x) = 2x$는 다음과 같다.
def derivative(x: float) -> float:
return 2 * x
이와 같이 미분함수가 구체적으로 주어지는 경우는 많지 않다. 따라서 여기서는 많은 경우 충분히 작은 $h$에 대한 함수의 변화율을 측정하면 미분값의 근사치를 사용할 수 있다는 사실을 확인하고자 한다.
아래 그림은 $h$가 작아질 때 두 점 $f(x+h)$ 와 $f(x)$ 지나는 직선이 변하는 과정을 보여준다. $h$가 0에 수렴하면 최종적으로 점 $x$에서의 접선이 되고 미분값 $f'(x)$는 접선의 기울기가 된다.
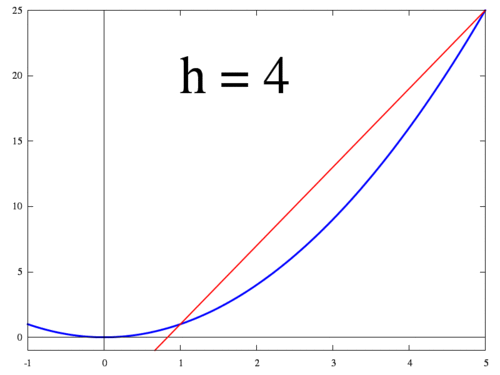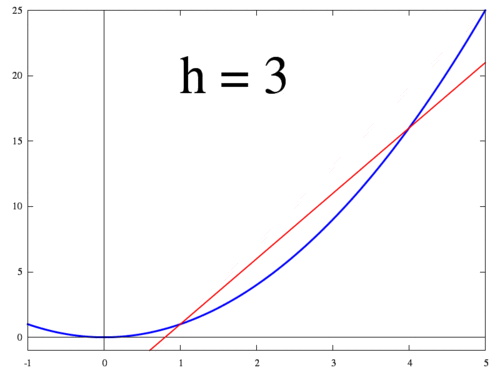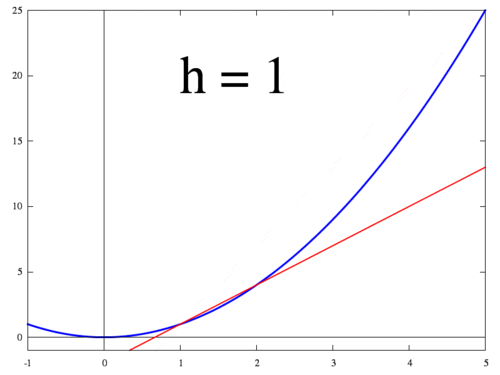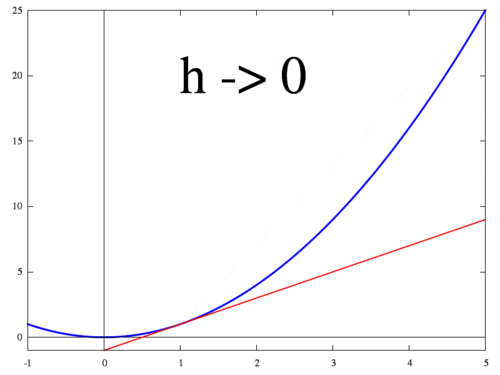 <출처 > 위키:미분
<출처 > 위키:미분
아래 코드는 임의의 단변수 함수에 대해 함수 변화율을 구해주는 함수를 간단하게 구현한 것이다.
Callable은 함수에 대한 자료형을 가리킨다. Callable[[float], float]: 부동소수점을 하나 받아 부동소수점을 계산하는 함수들의 클래스를 가리킴.different_quotient() 함수가 사용하는 세 인자와 리턴값의 자료형은 다음과 같다. f: Callable[[float], float]x: floath: floatfloat): $f'(x)$의 근사치from typing import Callable
def difference_quotient(f: Callable[[float], float],
x: float,
h: float) -> float:
"""
함수 f의 x에서의 미분값 근사치 계산
f: 미분 대상 함수
x: 인자
h: x가 변하는 정도
"""
return (f(x + h) - f(x)) / h
아래 코드는 square()의 도함수 derivative() 를 difference_quotient()를
이용하여 충분히 근사적으로 구현할 수 있음을 그래프로 보여준다.
근사치 계산을 위해 h=0.001 를 사용한다.
import matplotlib.pyplot as plt
h = 0.001
xs = range(-10, 11)
actuals = [derivative(x) for x in xs]
estimates = [difference_quotient(square, x, h) for x in xs]
plt.title("Actual Derivatives vs. Estimates")
# 실제 도함수 그래프(빨간색 점)
plt.plot(xs, actuals, 'r.', label='Actual')
# 근사치 그래프(검은색 +)
plt.plot(xs, estimates, 'k+', label='Estimates')
plt.legend()
plt.show()

다변수 함수의 그레이디언트는 매개변수 각가에 대한 편도함수(partial derivative)로 구성된 벡터로 구성된다. 예를 들어, $i$번째 편도함수는 $i$번째 매개변수를 제외한 다른 모든 매개변수를 고정하는 방식으로 계산된다.
$f$가 다변수 함수(다차원 함수)일 때, 점 $\mathbf{x}$에서의 $i$번째 도함수는 다음과 같다.
$$ \frac{\partial}{\partial x_i}f(\mathbf x) = \lim_h \frac{f(\mathbf{x}_h) - f(\mathbf x)}{h} $$여기서 $\mathbf{x}_h$는 $\mathbf x$의 $i$번째 항목에 $h$를 더한 벡터를 가리킨다. 즉, $\frac{\partial}{\partial x_i} f(\mathbf x)$ 는 $x_i$가 아주 조금 변할 때 $f(\mathbf x)$가 변하는 정도, 즉 함수 $f$의 $x$에서의 $i$번째 편미분값이 된다. 이때 함수 $\frac{\partial}{\partial x_i}f$ 를 함수 $f$의 $i$번째 편도함수라 부른다.
아래 코드에서 정의된 partial_difference_quotient는 주어진 다변수 함수의 $i$번째
편도함수의 근사치를 계산해주는 함수이다.
사용되는 매개변수는 difference_quotient() 함수의 경우와 거의 같다.
다만 i번째 편도함수의 근사치를 지정하기 위해 i번째 매개변수에만 h가 더해짐에 주의하라.
def partial_difference_quotient(f: Callable[[Vector], float],
v: Vector,
i: int,
h: float) -> float:
"""
함수 f의 v에서의 i번째 편미분값 근사치 계산
f: 편미분 대상 함수
v: 인자 벡터
i: i번째 인자를 가리킴
h: 인자 v_i가 변하는 정도
"""
# v_i에 대해서만 h 더한 벡터
w = [v_j + (h if j == i else 0) for j, v_j in enumerate(v)]
return (f(w) - f(v)) / h
다음 estimate_gradient() 함수는 편미분 근사치를 이용하여
그레이디언트의 근사치에 해당하는 벡터를 리스트로 계산한다.
근사치 계산에 사용된 h의 기본값은 0.0001이다.
def estimate_gradient(f: Callable[[Vector], float],
v: Vector,
h: float = 0.0001):
return [partial_difference_quotient(f, v, i, h) for i in range(len(v))]
그레이디언트를 두 개의 함수값의 차이를 이용하여 근사치로 계산하는 방식은 계산 비용이 크다.
벡터 v의 길이가 $n$이면 estimate_gradient() 함수를 호출할 때마다
f를 $2n$ 번 호출해야 하기 때문이다.
따라서 앞으로는 그레이디언트 함수가 수학적으로 쉽게 계산되는 경우만을
사용하여 경사하강법의 용도를 살펴볼 것이다.
앞서 정의한 제곱함수 sum_of_squares() 는 v가 0 벡터일 때 가장 작은 값을 갖는다.
이 사실을 경사하강법을 이용하여 확인해보자.
먼저, sum_of_squares() 함수의 그레이디언트는 다음과 같이 정의된다.
아래 코드는 리스트를 이용하여 그레이디언트를 구현하였다.
def sum_of_squares_gradient(v: Vector) -> Vector:
return [2 * v_i for v_i in v]
아래 코드는 임의의 지점(v)에서 계산된 그레이디언트에 스텝(step)이라는 특정 상수를 곱한 값을
더해 새로운 지점을 계산하는 함수를 구현한다.
add, scalar_multiply, distance 등은 선형대수 부분에서 정의한 linear_algebra 모듈에서 가져온다.add(v, step): 스텝사이즈가 음수이면 그레이디언트가 가리키는 방향의 반대방향으로 지정된 비율만큼 움직인 벡터.import random
from scratch.linear_algebra import distance, add, scalar_multiply
# v에서의 그레이디언트를 구한 후 스텝이 지정한 크기 비율과 방향으로 이동한 새로운 벡터 v'을 계산한다.
def gradient_step(v: Vector, gradient: Vector, step_size: float) -> Vector:
step = scalar_multiply(step_size, gradient)
return add(v, step)
이제 임의의 지점에서 출발하여 gradient_step을 충분히 반복하면
제곱함수의 최솟점에 충분히 가깝게 근사할 수 있음을 아래 코드가 보여준다.
실제로 1.0e-07보다 작다.
random.seed(42): 실행할 때마다 동일한 결과를 보장해준다. 사용하지 않으면 매번 다른 결과가 나옴.grad: 이동할 때마다 계산된 그레이디언트. 최종적으로 0 벡터에 가까운 값을 갖게 됨.if epoch%100 == 0: 위치 이동을 100번 할 때마다 현재 위치 확인epoch(에포크): 여기서는 그레이디언트 계산 횟수. 즉, 이동횟수를 가리킴.step_size=-0.01: 그레이디언트 반대 방향, 즉, 최솟값 지점을 향해 이동할 때 사용되는 크기 비율# 임의의 지점 선택
random.seed(42)
v = [random.uniform(-10, 10) for i in range(3)]
# gradient_step 1000번 반복
for epoch in range(1000):
grad = sum_of_squares_gradient(v)
v = gradient_step(v, grad, -0.01)
if epoch%100 == 0:
print(epoch, v)
print("\n----\n")
print(f"그레이디언트의 최종 값: {grad}")
print(f"v의 최후 위치와 최솟점 사이의 거리: {distance(v, [0, 0, 0])}")
0 [2.732765249774521, -9.309789197635727, -4.409425359965263] 100 [0.3624181137897112, -1.2346601088642208, -0.5847760329896551] 200 [0.048063729299005625, -0.16374007531854073, -0.07755273779298358] 300 [0.006374190434279768, -0.02171513607091833, -0.010285009644527733] 400 [0.0008453423045827667, -0.002879851701919325, -0.0013639934114305214] 500 [0.00011210892101281368, -0.00038192465375128993, -0.00018089220046728499] 600 [1.4867835316559317e-05, -5.065067796575345e-05, -2.3989843290795995e-05] 700 [1.971765716798422e-06, -6.717270417586384e-06, -3.1815223632100903e-06] 800 [2.6149469369030636e-07, -8.908414196052704e-07, -4.2193208287814765e-07] 900 [3.467931014604295e-08, -1.1814299344070243e-07, -5.5956445449048146e-08] ---- 그레이디언트의 최종 값: [9.57758165411209e-09, -3.262822016281278e-08, -1.5453808714914104e-08] v의 최후 위치와 최솟점 사이의 거리: 1.830234305038648e-08
앞서 사용된 코드에서 에포크(epoch)는 이동 횟수를 가리키며, 에포크를 크게 하면 최솟값 지점에 보다 가까워진다. 하지만 항상 수렴하는 방향으로 이동하는 것은 아니다. 하지만 여기서는 스텝 크기를 너무 크게 지정하지만 않으면 항상 최솟값에 수렴하는 볼록함수만 다룬다. 스텝 크기에 따른 수렴속도는 다음과 같다.
하지만 다루는 함수에 따른 적당한 스텝의 크기가 달라지며, 보통 여러 실혐을 통해 정해야 한다.
경사하강법을 이용하여 주어진 데이터들의 분포에 대한 선형 모델을 구하는 방법을 선형회귀(linear regression)라 부른다.
먼저 $y = f(x) = 20*x + 5$ 일차함수의 그래프에 해당하는 데이터를 구한다. 여기서 $x$는 -0.5에서 0.5 사이에 있는 100개의 값으로 주어지며, $y$값에 약간의 잡음(가우시안 잡음)이 추가된다.
# x는 -0.5에서 0.5 사이
xs = [x/100 for x in range(-50, 50)]
# 약간의 잡음 추가 (가우시안 잡음)
error = [random.randrange(-100,100)/100 for _ in range(-50, 50)]
# y = 20*x + 5 + 가우시안 잡음
ys = [20*x + 5 + e for x, e in zip(xs, error)]
# (x,y) 좌표값들의 리스트
inputs = list(zip(xs, ys))
아래 프로그램은 잡음이 포함되어 직선으로 그려지지 않는 데이터의 분포를 보여준다.
plt.plot(xs, ys, 'r.')
plt.show()

이제 위 그래프를 선형적으로 묘사하는 함수를 경사하강법을 이용하여 구현한다. 구현 대상은 아래 모양의 함수이다.
$$ \hat y = f(x) = \theta_0 x + \theta_1 $$위 그래프를 가장 잘 묘사하는 직선을 구해야 한다. 즉, 적절한 $\theta_0$와 $\theta_1$을 구해야 한다.
경사하강법을 적용하려면 최소화 대상함수를 정해야 한다. 여기서는 예측치 $\hat y$와 실제 $y$ 사이의 오차의 평균제곱오차(mean squared error, MSE)를 계산하는 함수를 사용한다.
$$ \textrm{MSE}(\theta_0, \theta_1) = \sum_{y \in ys} (\hat y - y)^2 = \sum_{x \in \textrm{xs}} (\theta_0 x + \theta_1 - y)^2 $$즉, MSE를 최소로 하는 $\theta_0, \theta_1$을 구해야 한다. MSE의 그레이디언트는 다음과 같다.
$$ \frac{\partial}{\partial \theta_0} \textrm{MSE}(\theta_0, \theta_1) = \sum_{x \in \textrm{xs}} 2(\hat y - y) x\, , \qquad \frac{\partial}{\partial \theta_1} \textrm{MSE}(\theta_0, \theta_1) = \sum_{x \in \textrm{xs}} 2(\hat y - y) $$아래 코드는 특정 x에 대한 실제 값 y와 예측치 $\hat y$ 사이의 제곱오차와 제곱오차의 그레이디언트를 계산한다.
slope: $\theta_0$ (기울기)intercept: $\theta_1$ (절편)predicted: $\hat y$error: $(\hat y - y)$grad: $(2(\hat y - y) x, 2(\hat y - y))$def linear_gradient(x: float, y: float, theta: Vector) -> Vector:
# 기울기와 절편
slope, intercept = theta
# 예측치
predicted = slope * x + intercept
# 오차
error = (predicted - y)
# 제곱 오차
squared_error = error ** 2
# 특정 x에 대한 제곱오차의 그레이디언트 항목
grad = [2 * error * x, 2 * error]
return grad
이제 임의의 $\theta = (\theta_0, \theta_1)$로 시작한 후에 경사하강법으로 평균제곱오차의 최솟값 지점을 구할 수 있다.
vector_mean: 벡터 항목들의 평균값 계산epoch(에포크): 5000회 반복learning_rate: 스텝 크기. 보통 학습률이라 부름.아래 코드에서 사용한 학습률은 0.001이다.
from scratch.linear_algebra import vector_mean
# 임의의 기울기와 절편으로 시작
theta = [random.uniform(-1, 1), random.uniform(-1, 1)]
learning_rate = 0.001
for epoch in range(5000):
# 평균 제곱 오차 계산 (전체 훈련 데이터 대상)
grad = vector_mean([linear_gradient(x, y, theta) for x, y in inputs])
# theta 값 업데이트. 그레이디언트 반대 방향으로 지정된 학습률 비율로 이동
theta = gradient_step(theta, grad, -learning_rate)
# 500번에 한 번 학습과정 확인
if epoch % 500 == 0:
print(epoch, theta)
slope, intercept = theta
print(f"최종 기울기: {slope:.3f}")
print(f"최종 절편: {intercept:.3f}")
0 [-0.5573631781037754, -0.3409606698035382] 500 [1.0860605634068832, 2.9677764519232985] 1000 [2.6080336786406573, 4.18874863946214] 1500 [4.011976376077862, 4.642064339793808] 2000 [5.305013852497387, 4.812897015495151] 2500 [6.495163711496766, 4.879577951303121] 3000 [7.5903398484398314, 4.90767120517886] 3500 [8.598020889846392, 4.921296576290668] 4000 [9.525160097963871, 4.929341055389218] 4500 [10.378181475323187, 4.9350917239397925] 최종 기울기: 11.161 최종 절편: 4.940
그런데 최종 기울기가 11.398로 애초에 사용한 20과 차이가 크다. 이유는 학습률이 너무 낮아서 5000번의 에포크가 충북한 학습을 위해 부족했기 때문이다. 이에 대한 해결책은 보통 두 가지이다.
아래 코드는 먼저 에포크를 네 배 늘린 결과를 보여준다.
from scratch.linear_algebra import vector_mean
# 임의의 기울기와 절편으로 시작
theta = [random.uniform(-1, 1), random.uniform(-1, 1)]
learning_rate = 0.001
for epoch in range(20000):
# 평균 제곱 오차 계산 (전체 훈련 데이터 대상)
grad = vector_mean([linear_gradient(x, y, theta) for x, y in inputs])
# theta 값 업데이트. 그레이디언트 반대 방향으로 지정된 학습률 비율로 이동
theta = gradient_step(theta, grad, -learning_rate)
# 1000번에 한 번 학습과정 확인
if epoch % 1000 == 0:
print(epoch, theta)
slope, intercept = theta
print(f"최종 기울기: {slope:.3f}")
print(f"최종 절편: {intercept:.3f}")
0 [0.539845326196926, -0.8765658904200774] 1000 [3.5347058588398195, 4.120657569741477] 2000 [6.089146831484904, 4.807295221174362] 3000 [8.254060613242245, 4.909957251324375] 4000 [10.08698653375398, 4.932225333575831] 5000 [11.63858380675949, 4.942345701376079] 6000 [12.951998593477466, 4.949733516900191] 7000 [14.063789219509484, 4.955827987429306] 8000 [15.0049066769235, 4.960965378519356] 9000 [15.801551256517898, 4.965311213690506] 10000 [16.475901275838954, 4.968989518433547] 11000 [17.046730424738943, 4.972103106006536] 12000 [17.529930406587045, 4.974738713135767] 13000 [17.938953356610103, 4.976969721779518] 14000 [18.285186344872766, 4.978858243526626] 15000 [18.57826838869039, 4.980456854364114] 16000 [18.826358799830466, 4.981810059132508] 17000 [19.036364337180647, 4.982955530628767] 18000 [19.21413148874078, 4.983925158418778] 19000 [19.36460923600656, 4.984745936634814] 최종 기울기: 19.492 최종 절편: 4.985
반면에 아래 코드는 학습률을 0.01로 키웠다.
from scratch.linear_algebra import vector_mean
# 임의의 기울기와 절편으로 시작
theta = [random.uniform(-1, 1), random.uniform(-1, 1)]
learning_rate = 0.01
for epoch in range(5000):
# 평균 제곱 오차 계산 (전체 훈련 데이터 대상)
grad = vector_mean([linear_gradient(x, y, theta) for x, y in inputs])
# theta 값 업데이트. 그레이디언트 반대 방향으로 지정된 학습률 비율로 이동
theta = gradient_step(theta, grad, -learning_rate)
# 500번에 한 번 학습과정 확인
if epoch % 500 == 0:
print(epoch, theta)
slope, intercept = theta
print(f"최종 기울기: {slope:.3f}")
print(f"최종 절편: {intercept:.3f}")
0 [0.6757583873253522, 0.6957201300303815] 500 [11.706690051576645, 4.942804228398626] 1000 [16.50780846999213, 4.969163560245711] 1500 [18.593137756203685, 4.98053795906695] 2000 [19.498884502023184, 4.9854783387029045] 2500 [19.89228863870891, 4.98762415462158] 3000 [20.0631607014304, 4.988556173271237] 3500 [20.137377668401463, 4.988960988407408] 4000 [20.16961323750889, 4.9891368167500385] 4500 [20.18361450915995, 4.9892131864390965] 최종 기울기: 20.190 최종 절편: 4.989
위 결과를 비교했을 때 학습률을 키우는 것이 보다 효과적이다. 최종적으로 구해진 기울기와 절편을 이용하여 처음에 주어진 데이터의 분포를 선형적으로 학습한 1차함수의 그래프는 다음과 같다.
# 예측치
zs = [slope *x + intercept for x in xs]
# 실제 데이터 분포
plt.plot(xs, ys, 'r.', label='Actuals')
# 예측치 그래프
plt.plot(xs, zs, 'b-', label='Estimates')
plt.title("Linear Regression")
plt.legend()
plt.show()

앞서 사용한 경사하강법은 주어진 데이터셋 전체를 대상으로 평균제곱오차와 그레이디언트를 계산하였다. 이런 방식을 배치 경사하강법이라 부른다.
주의: 배치(batch)는 원래 하나의 묶음을 나타내지만 여기서는 주어진 (훈련) 데이터셋 전체를 가리키는 의미로 사용된다.
그런데 사용된 데이터셋의 크기가 100이었기 때문에 계산이 별로 오래 걸리지 않았지만, 데이터셋이 커지면 그러한 계산이 매우 오래 걸릴 수 있다. 실전에서 사용되는 데이터셋의 크기는 몇 만에서 수십억까지 다양하며, 그런 경우에 적절한 학습률을 찾는 과정이 매우 오래 걸릴 수 있다.
데이터셋이 매우 큰 경우에는 따라서 아래 두 가지 방식을 추천한다.
배치 경사하강법과는 달리 미니매치 경사하강법(mini-batch gradient descent)은 일정 크기의 훈련 데이터를 대상으로 그레이디언트를 계산한다.
예를 들어, 전체 데이터셋의 크기가 1000이고 미니배치의 크기를 10이라 하면, 배치 경사하강법에서는 하나의 에포크를 돌 때마다 한 번 MSE와 그레이디언트를 계산하였지만 미니배치 경사하강법에서는 10개의 데이터를 확인할 때마다 MSE와 그레이디언트를 계산하여 하나의 에포크를 돌 때마다 총 100번 기울기와 절편을 업데이트한다.
아래 코드에서 정의된 minibatches() 함수는 호출될 때마다
batch_size로 지정된 크기의 데이터 세트를 전체 데이터셋에서
선택해서 내준다.
데이터를 선택하는 방식은 다음과 같다.
minibatches() 함수는 제너레이터이다.
즉, 요구될 때마다 항목을 생성하여 리턴하는 함수이다. batch_size) 만큼씩 구분하여
batch_starts 리스트에 저장한다.shuffle) 옵션이 True일 경우, batch_starts에 포함된 항목들의 순서를 무작위로 섞는다.batch_starts 에 포함된 인데스를 기준으로 지정된 미니배치 크기만큼의
데이터를 다음 MSE, 그레이디언트 계산용으로 내어 준다.from typing import List, Iterator
# 제너레이터 함수 정의
def minibatches(dataset: List[float],
batch_size: int,
shuffle: bool = True) -> Iterator[List[float]]:
"""
dataset: 전체 데이터셋
batch_size: 미니배치 크기
shuffle: 섞기 옵션
리턴값: 이터레이터
"""
# 0번 인덱스부터 시작하여, batch_size 배수 번째에 해당하는 인덱스만 선택
batch_starts = [start for start in range(0, len(dataset), batch_size)]
# shuffle 옵션이 참이면 인덱스 섞기
if shuffle: random.shuffle(batch_starts)
# batch_starts에 포함된 인덱스를 기준으로 해서 미니배치 크기만큼씩 선택해서
# 다음 MSE와 그레이디언트 계산에 필요한 훈련 데이터 세트를 지정함.
for start in batch_starts:
end = start + batch_size
yield dataset[start:end]
이제 미니배치 경사하강법을 이전에 사용했던 데이터에 대해 적용한다.
학습률(learning_rate)을 0.001로 하면 학습이 제대로 이루어지지 않는다.
에포크 수를 키우거나 합습률을 크게 해야 한다.
# 임의의 기울기와 절편으로 시작
theta = [random.uniform(-1, 1), random.uniform(-1, 1)]
# 학습률 지정
learning_rate = 0.001
# 1000번의 에포크
for epoch in range(1000):
# 미니배치의 크기를 20으로 지정함
# 따라서 한 번의 에포크마다 5번 MSE와 그레이디언트 계산 후 기울기와 절편 업데이트
# 섞기 옵션 사용
for batch in minibatches(inputs, batch_size=20):
grad = vector_mean([linear_gradient(x, y, theta) for x, y in batch])
theta = gradient_step(theta, grad, -learning_rate)
# 100개의 에포크가 지날 때마다 학습 내용 출력
if epoch % 100 == 0:
print(epoch, theta)
slope, intercept = theta
print(f"최종 기울기: {slope:.3f}")
print(f"최종 절편: {intercept:.3f}")
0 [-0.18096617572366355, -0.810253155496382] 100 [1.4325823295978932, 2.7965832049687727] 200 [2.9277291181808662, 4.127583024520555] 300 [4.307256114408177, 4.6201205624228345] 400 [5.577858834315078, 4.805372329280058] 500 [6.747297927532496, 4.877973082222024] 600 [7.823358363323769, 4.9075106536945095] 700 [8.813363542511828, 4.9227014341159645] 800 [9.724173605813512, 4.930098309332715] 900 [10.562099366999867, 4.935898279024058] 최종 기울기: 11.326 최종 절편: 4.940
학습률을 0.01로 키우면 좋은 결과가 나온다.
# 임의의 기울기와 절편으로 시작
theta = [random.uniform(-1, 1), random.uniform(-1, 1)]
# 학습률 지정
learning_rate = 0.01
# 1000번의 에포크
for epoch in range(1000):
# 미니배치의 크기를 20으로 지정함
# 따라서 한 번의 에포크마다 5번 MSE와 그레이디언트 계산 후 기울기와 절편 업데이트
# 섞기 옵션 사용
for batch in minibatches(inputs, batch_size=20):
grad = vector_mean([linear_gradient(x, y, theta) for x, y in batch])
theta = gradient_step(theta, grad, -learning_rate)
# 100개의 에포크가 지날 때마다 학습 내용 출력
if epoch % 100 == 0:
print(epoch, theta)
slope, intercept = theta
print(f"최종 기울기: {slope:.3f}")
print(f"최종 절편: {intercept:.3f}")
0 [1.0089547406154515, 0.9789387260040882] 100 [11.920008658960944, 4.952894140709578] 200 [16.630466145513115, 4.970879458498564] 300 [18.65959750842576, 4.983489508744] 400 [19.533544758414724, 4.986114887570471] 500 [19.910159234650248, 4.9876175552247615] 600 [20.072120246973697, 4.988277830931272] 700 [20.141813699267466, 4.989044796751943] 800 [20.171950036505514, 4.989673862726055] 900 [20.18490980813245, 4.988704425280094] 최종 기울기: 20.190 최종 절편: 4.989
학습률을 0.01로 두고 에포크를 3000으로 늘려도 성능이 그렇게 좋아지지 않는다.
# 임의의 기울기와 절편으로 시작
theta = [random.uniform(-1, 1), random.uniform(-1, 1)]
# 학습률 지정
learning_rate = 0.01
# 3000번의 에포크
for epoch in range(3000):
# 미니배치의 크기를 20으로 지정함
# 따라서 한 번의 에포크마다 5번 MSE와 그레이디언트 계산 후 기울기와 절편 업데이트
# 섞기 옵션 사용
for batch in minibatches(inputs, batch_size=20):
grad = vector_mean([linear_gradient(x, y, theta) for x, y in batch])
theta = gradient_step(theta, grad, -learning_rate)
# 100개의 에포크가 지날 때마다 학습 내용 출력
if epoch % 100 == 0:
print(epoch, theta)
slope, intercept = theta
print(f"최종 기울기: {slope:.3f}")
print(f"최종 절편: {intercept:.3f}")
0 [-0.818987279044814, 0.5496759496355055] 100 [11.132254675200233, 4.944402547449223] 200 [16.29128890751974, 4.967275599762484] 300 [18.51315652813586, 4.978364613062517] 400 [19.470399111844596, 4.984337308055089] 500 [19.882668827278895, 4.988157388454654] 600 [20.060140900004065, 4.987966154755475] 700 [20.136885552244106, 4.987828522542775] 800 [20.16977510712028, 4.988976100905835] 900 [20.183962972393914, 4.989098169073801] 1000 [20.19002718033645, 4.989306092251666] 1100 [20.19268900836928, 4.989013649684174] 1200 [20.193941008879644, 4.98931327368746] 1300 [20.194440751083505, 4.988662935916931] 1400 [20.194676502572356, 4.989409414992472] 1500 [20.19501205890768, 4.989279358430207] 1600 [20.194844639671665, 4.9895094830280255] 1700 [20.195038900604747, 4.989915517219994] 1800 [20.195104991373057, 4.988570101328778] 1900 [20.195111383724566, 4.989401145459436] 2000 [20.194820820191822, 4.988704721391355] 2100 [20.194956704659234, 4.989706094313501] 2200 [20.194893907702024, 4.989209975413154] 2300 [20.19482708931829, 4.989765252131663] 2400 [20.19497162191007, 4.990361301343332] 2500 [20.19504959681753, 4.989715152995273] 2600 [20.195037903439133, 4.989885179868943] 2700 [20.195048938410093, 4.989683544147567] 2800 [20.194794217945287, 4.988956630961846] 2900 [20.19472935840392, 4.9896646884885545] 최종 기울기: 20.194 최종 절편: 4.989
학습 과정을 살펴보면 기울기가 19.966 정도에서 더 이상 좋아지지 않는다. 이런 경우 특별히 더 좋은 결과를 얻을 수 없다는 것을 의미한다. 사실, 데이터셋을 지정할 때 가우시안 잡음을 추가하였기에 완벽한 선형함수를 찾는 것은 애초부터 불가능하다. 따라서 위 결과를 미니배치 경사하강법을 사용한 선형회귀로 얻을 수 있는 최선으로 볼 수 있다.
확률적 경사하강법(stochastic gradient descent, SGD)은 미니배치의 크기가 1인 미니배치 경사하강법을 가리킨다. 즉, 하나의 데이터를 학습할 때마다 그레이디언트를 계산하여 기울기와 절편을 업데이트 한다.
아래 코드는 주어진 데이터셋을 대상로 SGD를 적용하는 방식을 보여준다. 학습률을 0.001로 했음에도 불구하여 1000번의 에포크를 반복한 후에 이전에 0.01을 사용했던 경우와 거의 동일한 결과를 얻는다는 것을 확인할 수 있다.
theta = [random.uniform(-1, 1), random.uniform(-1, 1)]
# 학습률
learning_rate = 0.001
# 에포크는 1000
for epoch in range(1000):
for x, y in inputs:
grad = linear_gradient(x, y, theta)
theta = gradient_step(theta, grad, -learning_rate)
if epoch % 100 == 0:
print(epoch, theta)
slope, intercept = theta
print(f"최종 기울기: {slope:.3f}")
print(f"최종 절편: {intercept:.3f}")
0 [-0.15554810709612274, 1.509287732512692] 100 [16.342595331414632, 5.034998314265212] 200 [19.472338990801568, 4.997992330602081] 300 [20.06303054508488, 4.991008012136133] 400 [20.174514599453477, 4.989689828163571] 500 [20.19555552053715, 4.989441040970666] 600 [20.199526674641238, 4.989394086168721] 700 [20.200276169630307, 4.98938522416341] 800 [20.200417625419696, 4.9893835515945835] 900 [20.200444323050316, 4.989383235922631] 최종 기울기: 20.200 최종 절편: 4.989
학습률을 0.01로 하면 오히려 결과가 나빠진다.
theta = [random.uniform(-1, 1), random.uniform(-1, 1)]
# 학습률
learning_rate = 0.01
# 에포크는 1000
for epoch in range(1000):
for x, y in inputs:
grad = linear_gradient(x, y, theta)
theta = gradient_step(theta, grad, -learning_rate)
if epoch % 100 == 0:
print(epoch, theta)
slope, intercept = theta
print(f"최종 기울기: {slope:.3f}")
print(f"최종 절편: {intercept:.3f}")
0 [2.259915006214208, 6.8246196207535865] 100 [20.261030045940156, 4.990193171642614] 200 [20.26103222379059, 4.990192825899716] 300 [20.26103222379092, 4.990192825899663] 400 [20.26103222379092, 4.990192825899663] 500 [20.26103222379092, 4.990192825899663] 600 [20.26103222379092, 4.990192825899663] 700 [20.26103222379092, 4.990192825899663] 800 [20.26103222379092, 4.990192825899663] 900 [20.26103222379092, 4.990192825899663] 최종 기울기: 20.261 최종 절편: 4.990
앞서 살펴본 것에 따르면 확률적 경사하강법의 성능이 가장 좋았다. 하지만 이것은 경우에 따라 다르다. 배치 경사하강법, 미니배치 경사하강법, 확률적 경사하강법 각각의 장단점이 있지만 여기서는 더 이상 자세히 다루지 않는다.