사전 활용¶
주요 내용¶
파이썬에 내장되어 있는 컬렉션 자료형 중 사전에 대해 알아 본다.
사전(dictionaries): 키(keys)와 값(values)으로 이루어진 쌍(pairs)들의 집합
사용 형태: 집합기호 사용
eng_math = {'year': 2017, 'semester' : 2, 'subject': 'Data Science'}특징
- 키로 사용될 수 있는 자료형: 문자열 등 불변 자료형 값
- 값으로 사용될 수 있는 자료형: 임의의 값
사전은 가변 자료형이다.
사전이름[키이름] = 값을 이용해 특정 항목의 키에 해당하는 값을 변경할 수 있다.update()메소드: 항목 추가del함수 또는pop()메소드: 특정 항목 삭제
items,keys,values등의 메소드를 이용하여 사전의 항목 확인 가능
오늘의 주요 예제¶
data 디렉토리에 저장된 scores_list.txt 파일은 선수 여덟 명의 점수를 담고 있다.
txt
Name Score
player1 21.09
player2 20.32
player3 21.81
player4 22.97
player5 23.29
player6 22.09
player7 21.20
player8 22.16목표: 위 파일로부터 1~3등 선수의 이름과 기록을 아래와 같이 확인하기
txt
1등 player5 23.29
2등 player4 22.97
3등 player8 22.16주의: 이전에는 1~3등의 점수만 확인하였다. 하지만 이제는 선수 이름까지 함께 확인해야 한다.
참조: Head First Programming(한빛미디어) 5장
사전 활용¶
저장된 파일에서 데이터를 불러와서 한 줄씩 확인하는 방법은 다음과 같다.
result_f = open("data/scores_list.txt")
for line in result_f:
print(line.strip()) # strip 메소드 활용하기
result_f.close()
복습¶
앞 장에서 1~3등의 점수를 확인하였다.
result_f = open("data/scores_list.txt")
score_list = []
for line in result_f:
(name, score) = line.split()
try:
score_list.append(float(score))
except:
continue
result_f.close()
score_list.sort(reverse=True) # 리스트를 내림차순으로 정렬
print("The top scores were:")
print(score_list[0])
print(score_list[1])
print(score_list[2])
for 반복문을 이용하여 다음과 할 수도 있다.
result_f = open("data/scores_list.txt")
score_list = []
for line in result_f:
(name, score) = line.split()
try:
score_list.append(float(score))
except:
continue
result_f.close()
score_list.sort(reverse=True) # 리스트를 내림차순으로 정렬
print("The top scores were:")
for i in range(3):
print(score_list[i])
이제 위 코드를 수정하여 아래 결과를 얻고자 한다.
txt
1등 player5 23.29
2등 player4 22.97
3등 player8 22.16즉, 각 등수의 선수 이름까지 필요하다. 어떻게 하면 선수이름과 점수를 동시에 움직이게 할 수 있을까?
마이크로소프트의 엑셀 프로그램을 활용하면 매우 간단하다.
|
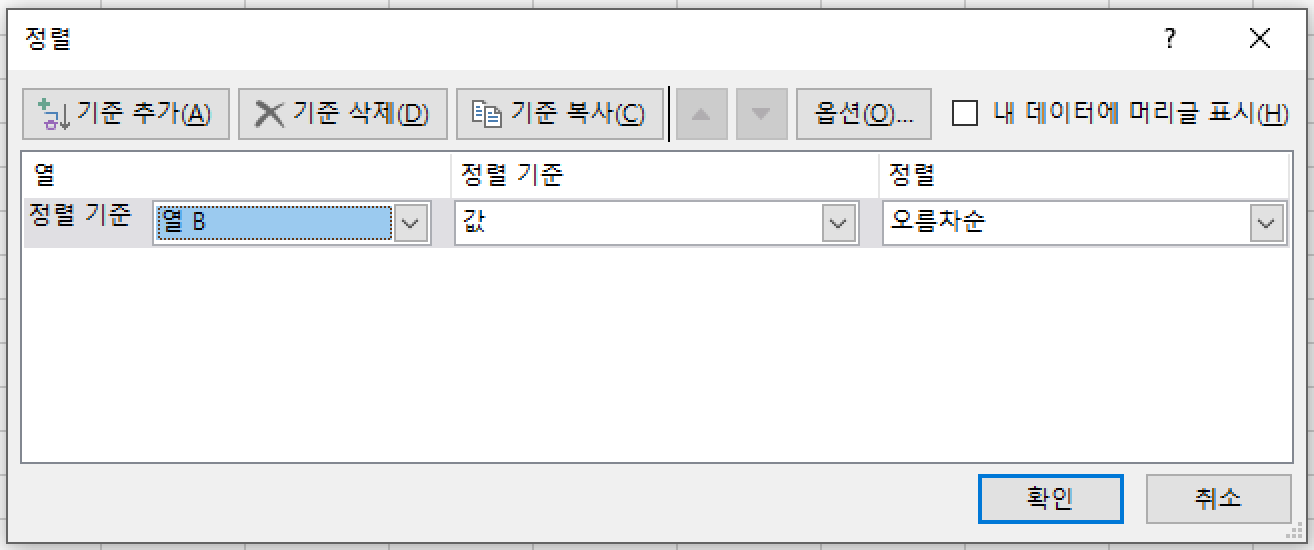
|
|
| 기존 기록표 | 점수 기준으로 정렬하기 | 정렬 후 기록표 |
두 개의 리스트로 쪼개기¶
먼저 앞서 사용한 방식을 약간 수정해서 기록들의 리스트와 선수이름들의 리스트를 생성해보자.
result_f = open("data/scores_list.txt")
score_list = []
name_list = [] # 선수이름 리스트 생성
for line in result_f:
(name, score) = line.split()
try:
score_list.append(float(score))
name_list.append(name) # 선수이름 추가
except:
continue
result_f.close()
print(score_list)
print(name_list)
현재 두 개의 리스트는 기존 테이블의 리스트의 순서와 동일한 순서대로 항목을 갖고 있다.
예를 들어, name_list 리스트의 첫 째 선수의 기록은 score_list 리스트의 첫 째 항목 값이다.
그런데 1~3등의 점수를 얻기 위해 score_list 리스트를 정렬하면 상위 세 명의 점수는 확인할 수 있었지만 어떤 선수가 수상을 해야 할지는 알 수 없었다.
어떻게 해야 할까? name_list 리스트도 정렬할까? 그런데 어떤 기준으로 정렬하나? 이름순으로? 그러면 A 또는 Z로 시작하는 선수가 항상 1등 아니면 꼴등이 되어 버리는 문제가 발생한다.
이런 문제는 두 개의 리스트를 다룰 때 항상 발생한다. 그리고 일반적으로 두 개의 리스트를 엑셀의 경우처럼 한 가지 기준으로 연동해서 정렬할 수는 없다. 따라서 다른 접근방식이 요구된다.
여기서는 사전 자료형을 이용하여 문제를 해결하고자 한다. 하지만 해결법을 설명하기 전에 사전 자료형을 간단한 예제를 통해 공부하고자 한다.
사전 자료형 예제¶
사전 자료형에 대한 이해는 어학공부에 사용하는 사전을 떠올리면 쉽다. 영어 사전의 경우 '단어 와 뜻'으로 이루어진 쌍들의 집합이라고 생각할 수 있다. 사전 자료형도 동일하게 작동한다.
예를 들어, 평택, 수원, 제주의 현재 온도에 대한 정보가 아래와 같다고 하자.
Pyongtaek 22
Suwon 18
Jeju 25이제 사전 자료형을 이용하여 위 정보를 저장하고 활용하는 방법은 다음과 같다.
먼저 빈 사전을 선언한다.
city_temperature = {}
이제 원하는 자료들의 쌍을 입력한다. 예를 들어 '평택 온도는 22도' 라는 정보를 추가하고자 하면 아래와 같이 하면 된다.
city_temperature['Pyongtaek'] = 22
이제 평택의 정보가 추가되었음을 확인할 수 있다.
city_temperature
이제 수원과 제주의 정보를 추가하고 확인해보자.
city_temperature['Suwon'] = 18
city_temperature['Jeju'] = 25
city_temperature
주의: 사전 자료형에서 각 항목의 순서는 전혀 의미가 없다.
키(key) 와 키값(value)¶
앞서 살펴보았듯 사전자료형의 항목들은 콜론(:)으로 구분된 두 개의 값들의 쌍으로 이루어진다.
왼쪽에 있는 값을 키(key), 오른쪽에 위치하는 값은 키값(value)라 부른다.
예를 들어 city_temperature에 사용된 키들은 Pyeongtaek, Suwon, Jeju 등이고 각 키들에 대응하는 키값은 각각 22, 18, 25이다.
키에 해당하는 키값을 확인하고자 하면 아래와 같이 명령하면 된다.
city_temperature['Pyongtaek']
city_temperature['Jeju']
키만 모아 놓은 리스트¶
사전에 사용된 키들만 따로 모아놓은 리스트를 만들어주는 사전 자료형 메소드가 있다.
key_list = city_temperature.keys()
key_list
주의: 도시명들의 순서 전혀 중요하지 않다.
키값만 모아 놓은 리스트¶
사전에 사용된 키값들만 따로 모아놓은 리스트를 만들어주는 사전 자료형 메소드가 있다.
value_list = city_temperature.values()
value_list
각각의 항목을 리스트의 항목으로 묶는 방식¶
사전에 사용된 항목들을 튜플로 묶어 리스트를 만들 수 있다.
item_list = city_temperature.items()
item_list
사전 자료형 반복문¶
사전자료형을 반복문에 활용할 수 있다.
이를 위해 keys 메소드를 사용한다.
예를 들어, 도시와 온도를 동시에 추출하여 모두 보여주고자 할 경우 아래와 같이 하면 된다.
for key in city_temperature.keys():
print(key,"의 온도는", city_temperature[key], "도 이다.")
사실 keys 메소드를 굳이 사용하지 않아도 된다.
for key in city_temperature:
print(key,"의 온도는", city_temperature[key], "도 이다.")
사전 자료형의 메소드는 그리 많지 않다.
특정 자료형의 메소드를 확인하고자 하면 dir() 함수를 활용한다.
dir(city_temperature)
주요 메소드들의 활용을 살펴보자.
pop메소드: 키에 해당하는 항목을 삭제한다.
city_temperature.pop("Suwon")
print(city_temperature)
키가 존재하지 않으면 오류('KeyError')가 발생한다.
city_temperature.pop("Suwon")
print(city_temperature)
특정 키의 존재여부를 확인하려면 keys() 메소드와 in 연산자를 활용한다.
"Suwon" in city_temperature.keys()
"Jeju" in city_temperature.keys()
아니면 단순히 in 연산자를 활용할 수도 있다.
"Suwon" in city_temperature
"Jeju" in city_temperature
update메소드: 하나의 사전을 다른 자료형과 합칠 수 있다.
other_city_temperature = {'Ansung': 21, 'Yongin': 23}
city_temperature.update(other_city_temperature)
city_temperature
get메소드: 지정한 키(key)에 해당하는 키값(value)를 되돌려 준다.
city_temperature.get('Ansung')
선수이름과 기록 연동하기¶
이제 선수이름과 기록을 연동하여 기록순으로 정렬하는 방법을 다루고자 하며, 이를 위해 사전 자료형을 활용한다.
방식은 앞서 언급한 아래의 코드를 약간 수정하면 된다.
result_f = open("data/scores_list.txt")
score_dict = dict() # 빈 사전 생성
# 아래와 같이 선언해도 된다.
# score_dict = {}
for line in result_f:
(name, score) = line.split()
try:
score_dict[float(score)] = name # 점수와 선수이름의 쌍을 사전에 추가
except:
continue
result_f.close()
print(score_dict)
이제 score_dict를 기록 기준으로 오름차순으로 정렬하면 된다.
하지만 사전 자료형에는 sort() 메소드가 없다.
대신에 sorted() 함수를 적용할 수 있다.
즉, sorted() 함수를 이용하여 기록을 정렬한 후에 그 순서대로 키값을 읽으면 된다.
sorted(score_dict.keys())
내림차순으로 정렬하려면 reverse=True라는 키워드 인자를 추가한다.
for each_record in sorted(score_dict.keys(), reverse=True):
print(score_dict[each_record], each_record)
이제 코드를 정리하면 다음과 같다.
result_f = open("data/scores_list.txt")
score_dict = dict() # 빈 사전 생성
# 아래와 같이 선언해도 된다.
# score_dict = {}
for line in result_f:
(name, score) = line.split()
try:
score_dict[float(score)] = name # 점수와 선수이름의 쌍을 사전에 추가
except:
continue
result_f.close()
score_keys = sorted(score_dict.keys(), reverse=True)
for key in score_keys:
print("Name:", score_dict[key], ", Score:", key)
위 코드를 좀 더 수정하면 등수까지도 보여줄 수 있다.
result_f = open("data/scores_list.txt")
score_dict = dict() # 빈 사전 생성
# 아래와 같이 선언해도 된다.
# score_dict = {}
for line in result_f:
(name, score) = line.split()
try:
score_dict[float(score)] = name # 점수와 선수이름의 쌍을 사전에 추가
except:
continue
result_f.close()
score_keys = sorted(score_dict.keys(), reverse=True)
count = 1
for key in score_keys:
print(str(count)+"등은", score_dict[key], "이고, 점수는", key, "입니다.")
count = count+1
견본답안 1: break 명령문 활용
result_f = open("data/scores_list.txt")
score_dict = dict() # 빈 사전 생성
# 아래와 같이 선언해도 된다.
# score_dict = {}
for line in result_f:
(name, score) = line.split()
try:
score_dict[float(score)] = name # 점수와 선수이름의 쌍을 사전에 추가
except:
continue
result_f.close()
score_keys = sorted(score_dict.keys(), reverse=True)
count = 1
for key in score_keys:
print(str(count)+"등은", score_dict[key], "이고, 점수는", key, "입니다.")
if count < 3:
count = count+1
else:
break
견본답안 2: 아래와 같이 range() 함수를 활용할 수도 있다.
result_f = open("data/scores_list.txt")
score_dict = dict() # 빈 사전 생성
# 아래와 같이 선언해도 된다.
# score_dict = {}
for line in result_f:
(name, score) = line.split()
try:
score_dict[float(score)] = name # 점수와 선수이름의 쌍을 사전에 추가
except:
continue
result_f.close()
score_keys = sorted(score_dict.keys(), reverse=True)
for i in range(3):
key = score_keys[i]
print(str(i+1)+"등은", score_dict[key], "이고, 점수는", key, "입니다.")
연습¶
수영 선수의 1등 - 3등까지 보여주는 코드를 수정하여, 특정 값 이상의 점수를 획득한 선수의 이름과 점수를 보여주는 코드를 작성해보자.
견본답안:
result_f = open('data/scores_list.txt')
score_dict = {}
for line in result_f:
(name, score) = line.split()
try:
score_dict[float(score)] = name
except:
continue
result_f.close()
score_keys = sorted(score_dict.keys(), reverse = True)
n_input = float(input('기준이 되는 점수: '))
for key in score_keys:
if key >= n_input:
print(score_dict[key])
연습¶
수영 점수의 기록에서 가장 높은 점수와 낮은 점수의 차를 구하는 코드를 작성하라
견본답안:
# 정렬된 코드 score_keys 가 있다면, `(score_keys[0] - score_keys[-1]` 로 구할 수도 있다.
result_f = open('data/scores_list.txt')
score_dict = {}
for line in result_f:
(name, score) = line.split()
try:
score_dict[float(score)] = name
except:
continue
result_f.close()
scores = score_dict.keys()
max_score = max(scores)
min_score = min(scores)
print('점수 차는', max_score - min_score)