인터넷에서 정보 구하기¶
프로그램은 기본적으로 데이터를 처리하기 위해 사용한다. 즉, 주어지거나 구한 데이터를 조작해서 원하는 결과를 만들어 낸다. 데이터는 증권시장과 관련된 숫자, 인터넷 검색창에서 언급되는 검색어, 지난 30년간의 기후 정보 등을 가리킨다.
인터넷이 발전하면서 점점 더 많은 데이터를 인터넷에서 구한다. 이를 위해 다음, 네이버, 구글 등이 제공하는 다양한 검색엔진이 사용되며, 사용자가 원하는 정보를 빠르고 정확하게 찾아주는 검색엔진의 중요성은 나날이 증가한다.
여기서는 인터넷 상에 존재하는 문서에서 원하는 정보를 파이썬 프로그램으로 확인하는 방법을 소개한다.
사용 예제: 커피 원두 가격 정보 확인하기¶
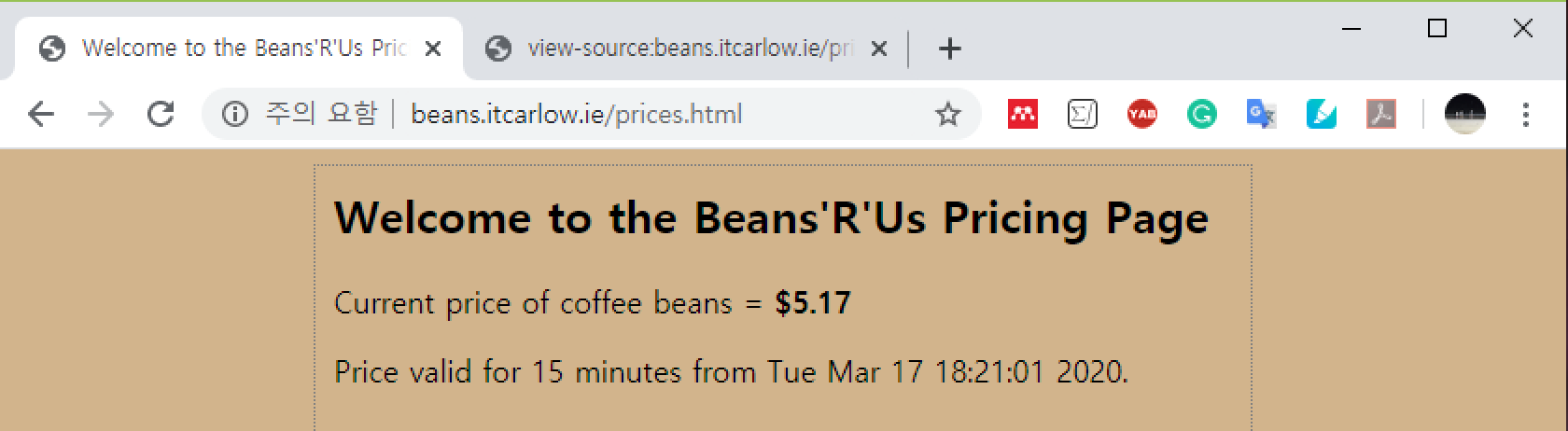
아래 웹페이지를 웹브라우저를 이용하여 방문하면 아래 사진처럼 보인다.
http://beans.itcarlow.ie/prices.html
주의: Head First Programming 교재에서 언급된 웹페이지 주소와 다름.
|
웹페이지에 포함된 내용은 아래와 같다.
Welcome to the Beans'R'Us Pricing Page
Current price of coffee beans = $5.17
Price valid for 15 minutes from Tue Mar 17 18:21:01 2020.즉, 2020년 3월 17일 오후 6시 21분 01초에 커피 원두 가격이 5달러 17센트(\$5.17)이다 라는 것이다.
주의사항¶
- 원두 가격과 시간은 웹페이지에 접속할 때마다 달라진다.
위 웹페이지 서버가 작동하지 않을 수도 있다. 그럴 경우 아래 링크를 대신 사용한다.
https://formal.hknu.ac.kr/lectures/HFProg/prices.html
- 해당 주소는 Beans'R'Us Pricing Page와 동일한 내용을 담고 있지만, 배경화면 색상과 디자인은 다르다.
- 또한 커피 원두 가격을 알려주는 서버가 아니라, 고정된 내용을 담은 웹페이지이다. 따라서 가격이 전혀 변하지 않는다.
- 하지만 특정 웹페이지에서 정보구하기를 연습하는 데는 나름 역할을 잘 수행한다.
인터넷 검색을 통한 정보 구하기¶
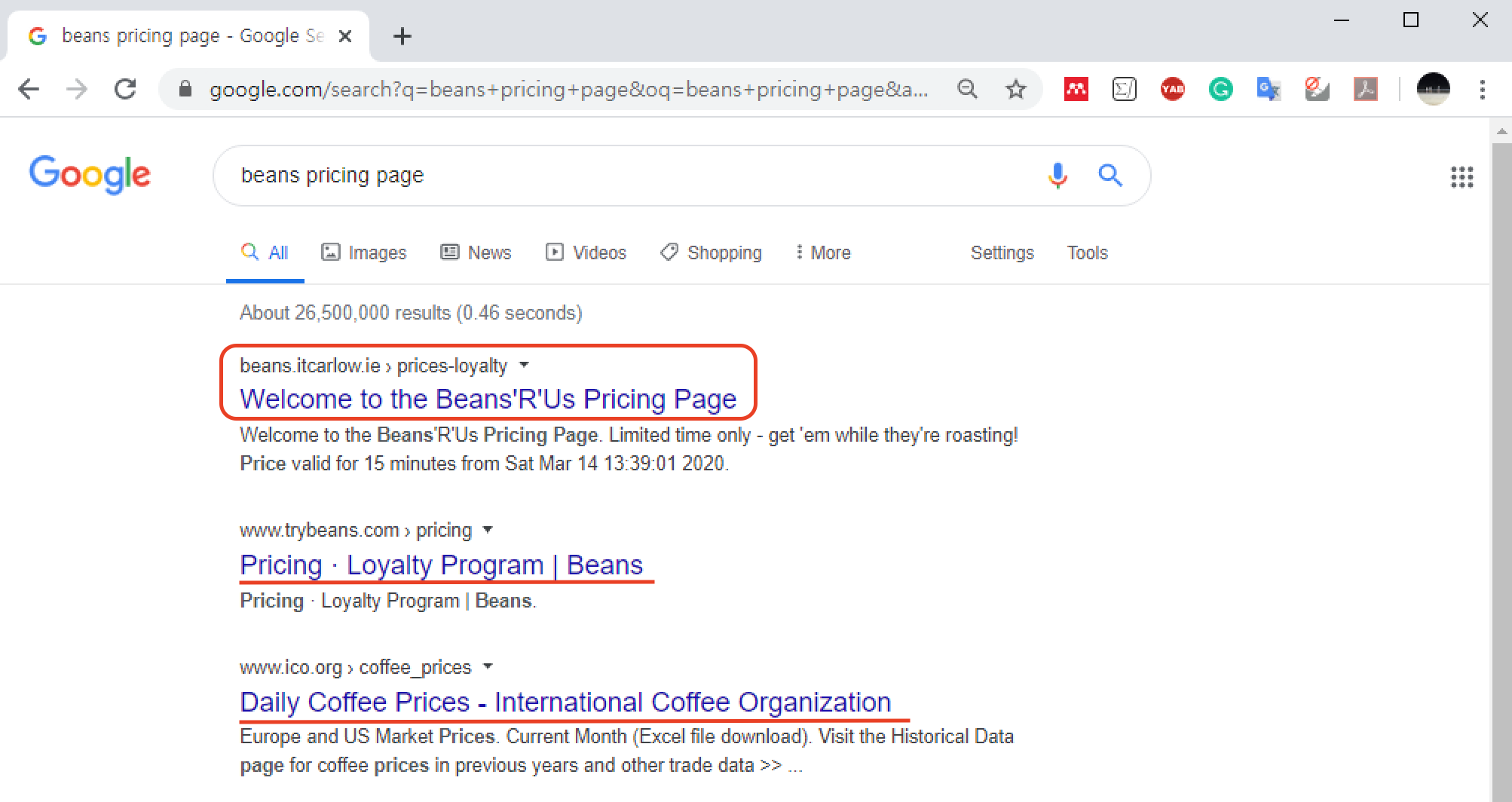
사람들은 보통 이런 식으로 커피 원두 가격을 확인한다. 예를 들어, 인터넷 검색창에 아래 세 단어를 입력하고 검색해보자
beans pricing page현재 강의노트를 작성하는 시점에서 구글검색 결과는 아래와 같으며, 상단에 위치한 세 개의 사이트는 모두 커피 원두 가격과 관련되어 있다. 특히, 맨 상단에 위치한 사이트는 앞서 언급한 Beans'R'Us 웹페이지와 관련되어 보인다. 실제로 두 웹페이지는 동일한 웹서버에 의해 작동된다. 나머지 두 웹사이트는 실제 커피 원두를 판매하는 온라인 쇼핑몰이다.
주의: 검색결과는 사용자와 브라우저에 따라 다를 수 있다.
|
이런 식으로 커피 원두의 가격을 인터넷 검색을 통해 찾은 웹페이지에 접속에서 쉽게 확인할 수 있다. 하지만 찾아야 하는 정보가 매우 많거나, 인터넷 문서가 길거나 복잡하면 원하는 정보를 눈으로 확인하기가 불가능해진다.
매우 긴 문서에서 원하는 정보를 찾기 위해 보통 Ctrl-F 키조합을 사용하여
검색을 시도한다.
하지만 예를 들어 백 개, 천 개, 심지어 몇 백만 개 등의 많은 문서에서 검색을 그런 방식으로 시도할 수는 없다.
이렇듯 웹브라우저를 이용하여 일일이 필요한 정보를 검색하는 일은 매우 불편하고 한계가 있으며,
때로는 불가능하다.
웹페이지와 소스코드¶
웹브라우저를 이용하여 웹페이지를 방문하지 않으면서 파이썬과 같은 프로그래밍언어를 이용해서 웹페이지의 소스코드를 불러와서 필요한 정보를 찾아내도록 할 수 있다.
작동방식은 다음과 같다.
- 파이썬이 제공하는 특정 함수에게 특정 웹페이지의 주소를 인자로 전달하여 실행한다.
- 그러면 해당 함수는 주소의 웹페이지를 관리하는 웹서버에게 웹페이지의 소스코드인 HTML 파일을 요구한다.
- 해당 함수는 웹서버로부터 받은 HTML 문서에 포함된 웹페이지 소스코드를 특정 문서로 만들어준다.
웹페이지 HTML 소스코드¶
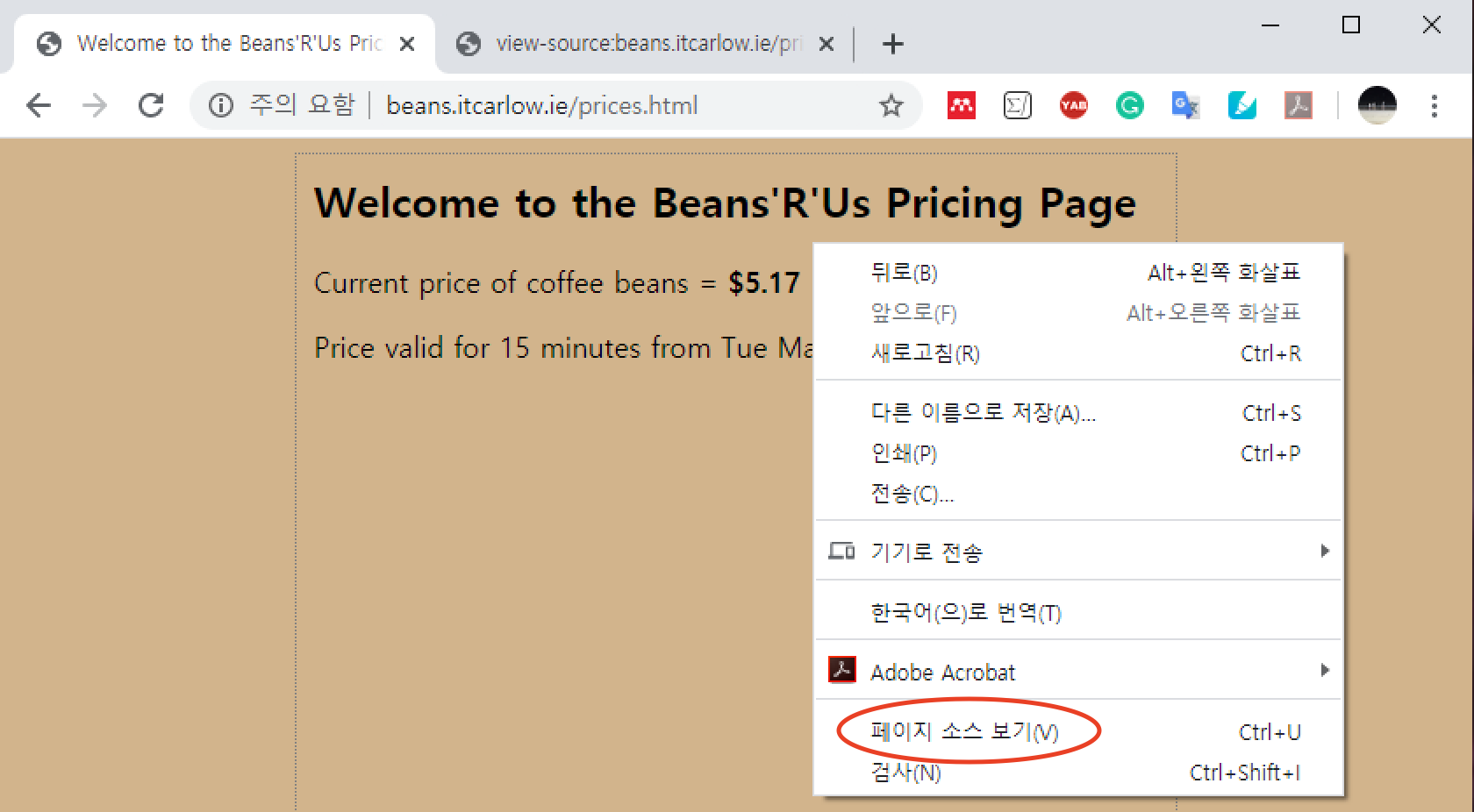
먼저 웹페이지의 소스코드가 무엇인지부터 알아야 한다. 예를 들어, Beans'R'Us Pricing Page에 방문했을 때 웹브라우저가 우리에게 보여주는 것은 HTML이라는 웹페이지 개발 전용 프로그래밍 언어로 작성된 해당 웹페이지의 소스코드(source code)를 예쁘게 포장해서 보여주는 것이다.
웹페이지 소스코드 확인법은 웹브라우저에 따라 다르다. 크롬 브라우저의 경우 마우스 오른쪽 버튼을 누른 후 '페이지 소스 보기(V)'를 선택하여 확인할 수 있다.
 |
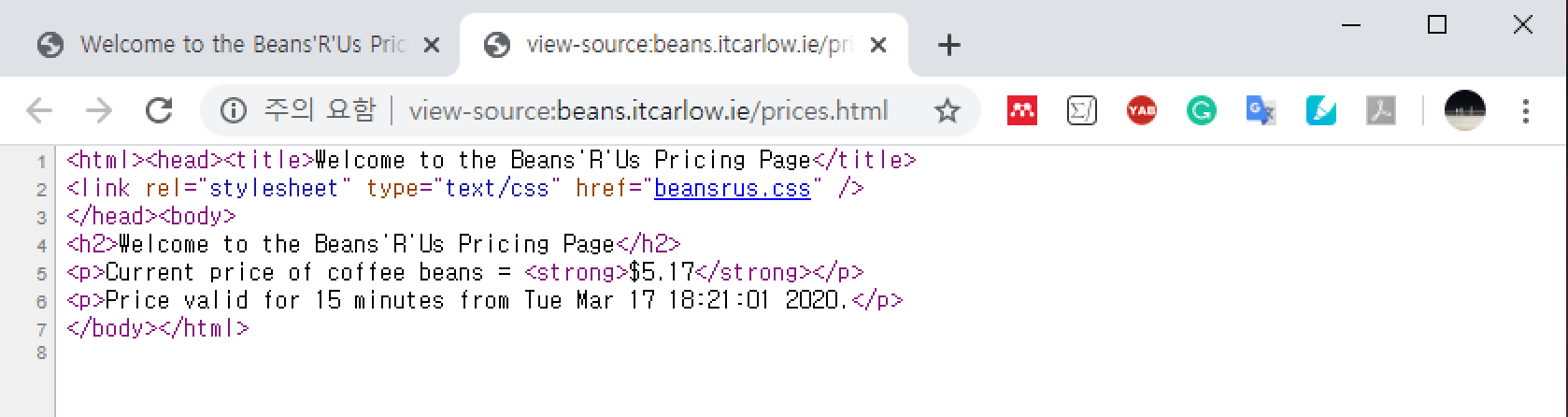
Beans'R'Us Pricing Page의 웹페이지 소스코드는 다음과 같다.
|
위 그림에서 보이는 소스코드는 커피 원두 가격과 같은 원하는 정보뿐만 아니라,
<html>, <head>, <link>, <h2>, <p> 등
폰트, 글자 크기, 주소 링크, 문단 구성 등과 관련된 웹페이지 설정 옵션 지정을
위한 HTML 언어 명령문도 포함하고 있다.
따라서 웹브라우저는 소스코드에 포함된 정보와 웹페이지 설정 옵션을 함께 고려하여 적절한 방식으로 내용을 사용자에게 전달한다.
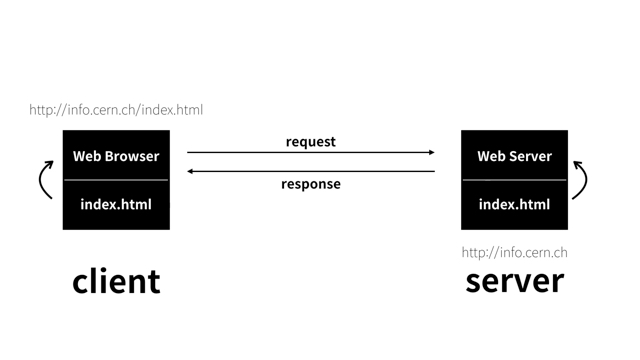
웹브라우저 역할: 서버와 클라이언트¶
앞서 언급한 소스코드 문서의 이름은 prices.html이며,
이 문서는 아래 주소의 웹서버에 저장되어 있다.
http://beans.itcarlow.ie/prices.html그리고 사용자가 특정 웹브라우저 주소창에 위 주소를 입력하고 리턴키를 누르면 웹브라우저는 아래 과정을 수행한다.
- 주소의 웹페이지를 관리하는 웹서버에게 주소가 가리키는 HTML 문서인
prices.html파일을 요구한다. - 해당 웹서버로부터 받은 HTML 문서의 내용을 해석하여 사용자에게 적절한 방식으로 문서 내용을 화면에 보여준다.
웹브라우저와 웹서버의 관계가 아래 그림에서처럼 클라이언트와 서버의 관계로 설명될 수 있다.
생활코딩 소개¶
HTML 언어를 이용하여 간단한 웹페이지와 웹서버를 구현하는 방법은 생각하는 것보다 훨씬 쉽다. 관련된 공부를 하고 싶다면 생활코딩 사이트에서 제공하는 WEB1 - HTML & Internet 강좌를 강추한다.
생활코딩은 웹서버 구현을 위해 필요한 지식과 정보를 다양한 실전 프로그래밍 예제를 학습하는 방법으로 전달하며, 학습주제에 따른 다양한 동영상 강좌를 제공한다. 이외에 파이썬을 포함하여 다양한 언어를 이용한 프로그래밍 기초 강좌도 함께 제공한다. 프로그래밍 학습에 관심 있는 초보자들이 효율적으로 프로그래밍을 학습할 수 있는 허브 역할을 수행한다.
웹페이지 소스코드 가져오기¶
웹브라우저를 이용하여 특정 웹페이지의 소스코드를 확인하여 그 안에서 원하는 정보를 구하는 일은 웹페이지를 직접 방문하여 정보를 구하는 일보다 더욱 힘든 일이다.
그런데 컴퓨터 프로그래밍을 이용하면 소스코드를 가져오고, 원하는 정보를 구하는 일을 자동으로 해결할 수 있다. 여기서는 파이썬이 제공하는 도구의 활용법을 예를 들어 설명한다.
urllib.request 모듈의 urlopen 함수¶
파이썬은 웹페이지 정보를 다루는 다양한 함수를 제공한다.
여기서는 urllib.request 라는 모듈에 포함된 urlopen 함수의 사용법을 소개한다.
전문 용어: 패키지와 모듈¶
urlopen 함수를 사용하려면 먼저 urllib.request 모듈을 불러와야(import) 한다.
그런데 그 전에 urllib, request, urlopen 등 전문용어로 사용된
단어들의 어원과 사용된 단어들의 순서를 살펴보는 것도 의미가 있다.
왜냐하면, 단어의 어원, 나열 순서, 역할이 서로 연관되어 있기 때문이다.
- 어원
url: 통합자원식별자(Uniform Resource Locator)의 약어.- 네트워크 상에서 자원이 위치한 주소 가리킴.
lib: 라이브러리(library)의 줄임말.
- 패키지와 모듈
- 특정 분야와 연관된 함수들을 기능별로 분류하여 분류된 함수들끼리 하나의 파이썬 코드파일에 저장. 이렇게 저장된 코드파일을 모듈이라 부름.
- 패키지(package): 특정 분야와 연관된 모듈을 모아놓은 폴더. 라이브러리라고도 부름.
- 의미
urllib: url과 관련된 패키지.urllib.request:urllib패키지에 포함된 모듈- 리크웨스트(request) 단어가 암시하듯이 인터넷 상에서 정보를 구해오는 것과 관련된 함수들이 정의되어 있는 모듈.
- 패키지와 모듈의 관계는 두 이름 사이에 점(
'.')을 찍어 구분.
urlopen:request모듈에 포함됨.- 지정된 웹주소의 소스코드를 가져와서 리턴값으로 내주는 함수.
urlopen 함수 활용¶
urlopen 함수를 이용하여
Beans'R'Us Pricing Page의
웹페이지 소스코드는 다음과 같이 불러온다.
import urllib.request
price_url = "http://beans.itcarlow.ie/prices.html"
price_page = urllib.request.urlopen(price_url)
page_text = price_page.read().decode("utf8")
print(page_text)
위 코드를 하나씩 살펴보면 다음과 같다.
urlopen 함수를 사용하려면 먼저 아래와 같이 urllib.request 모듈을 불러와야(import) 한다.
import urllib.request
주의: 모듈과 모듈의 활용에 대해서는 이후 자세히 다룬다. 여기서는 모듈을 활용해야 한다는 사실과 어떻게 활용하는지만 기억한다.
urlopen 함수를 활용하여 앞서 언급된 웹페이지의 HTML 소스코드를 가져오기 위해 아래와 같이 가져온다.
# 웹페이지 주소 저장
price_url = "http://beans.itcarlow.ie/prices.html"
# 웹페이지 소스코드 가져오기
price_page = urllib.request.urlopen(price_url)
이제 price_page 변수에는 urlopen 함수가 읽어 와서 내주는 값이 저장된다.
내주는 값에는 앞서 언급된 사이트의 HTML 소스코드가 포함되어 있다.
문서 내용을 확인한다.
# utf8로 디코딩해서 html 소스코드를 하나의 문자열로 저장
page_text = price_page.read().decode("utf8")
위 변수 할당 명령문에서 사용된 전문용어들의 어원과 의미는 다음과 같다.
- 어원
- 디코드(decode): 보텅 암호를 푼다, 즉 원래대로 돌려놓는다는 의미로 사용.
- utf8: 문자 인코딩(암호화)하는 방식
- 프로그래밍 언어 분야에서 거의 표준으로 사용되는 인코딩 방식임.
- MS 워드, 한컴오피스 등이 사용하는 인코딩 방식과 다름.
- utf8로 인코딩 된 문서는 거의 모든 문서편집기를 이용하여 다룰 수 있음.
- 의미
price_page.read():price_page변수에 값으로 할당된 문서에 포함된 내용을 읽음.price_page.read().decode("utf8"): 읽은 내용을 utf8 방식으로 디코딩.
객체와 메서드¶
price_page, read(), decode("utf8")를 점을 찍어 서로 구분하였지만
앞서 패키지와 모듈의 관계가 아니다.
여기서 점으로 구분되는 것은 객체(object)와 메서드(method)이다.
- 어원
- 객체: 여기서는 특정 자료형(클래스)의 값으로 이해할 수 있음.
- 메서드: 특정 자료형의 값에만 적용되는 함수.
- 의미
price_page:HTTPResponse라는 자료형(클래스)의 객체price_page.read():price_page객체에 포함된 내용을 읽어옮.read는HTTPResponse자료형(클래스)의 객체에만 적용되는 함수, 즉,HTTPresponse자료형의 메서드.read가 내주는 값은bytes자료형의 값임.
price_page.read().decode("utf8")read함수가 읽어온 문서 내용을 인자로 받아 utf8 방식으로 디코딩함.decode함수는bytes자료형의 값에만 적용되는 함수, 즉bytes자료형의 메서드.- 디코딩 결과는 문자열 자료형
str의 값, 즉 문자열임.
실제로 각 객체의 자료형을 확인하면 다음과 같다.
type(price_page)
type(price_page.read())
type(price_page.read().decode("utf8"))
print 함수의 역할¶
print 함수는 문자열 자료형을 나타내는 따옴표를 보여주지 않는다.
또한 줄바꾸기 기호(\n) 등을 직접
보여주는 대신에 실제로 줄바꾸기를 실행해서
격식을 갖춘 문장으로 보여준다.
print 함수를 사용하지 않으면
훨씬 읽기 어려운 순수 문자열에 불과함을
아래와 같이 확인할 수 있다.
page_text
즉, 앞서 언급하였듯이 하나의 상당히 긴 문자열이다.
실제로 줄바꿈 기호(\n)가 일곱 번 사용되었음을 확인 할 수 있다.

|
아래와 같이 print 함수를 호출했을 때의 결과에서 총 일곱 줄이 보인다.
줄바꿈을 일곱 번하면 여덟 줄이 나와야 하지만 마지막 줄바꿈 이후에 나오는 문장이 없어서
마지막 줄이 눈에 보이지 않아 일곱 줄로 보인다.
print(page_text)
문자열에서 정보 찾기¶
문자열 자료형의 값은 'Hello Python', '파이썬이 좋아요' 처럼
문자들로 구성된다.
파이썬에서 문자열 자료형은 str로 표시되며 string(스트링, 문자열)의 줄임말이다.
앞서 page_text 변수에 할당된 값은 HTML 소스코드도
하나의 문자열이다.
주의: 줄바꿈 기호(\n), 문자이며 공백(스페이스) 기호(`), 따옴표('`) 등도 모두 하나의 문자이다.
Beans'R'Us Pricing Page의
웹페이지 소스코드에서 가격 정보를 어떻게 구할 수 있는지를 살펴보자.
즉, page_text가 가리키는 문자열에서 커피 원두 가격 정보만을 추출해야 한다.
그러려면 소스코드 문자열에서 가격에 해당하는 부분(예를 들어 5.17)을 찾아서 읽어와야 한다.
단, 사람의 눈으로 확인하는 게 아니라
기계가 순전히 문자들의 모양만 보고 해당 숫자의 위치를 알아내야 한다.
문자열 인덱스¶
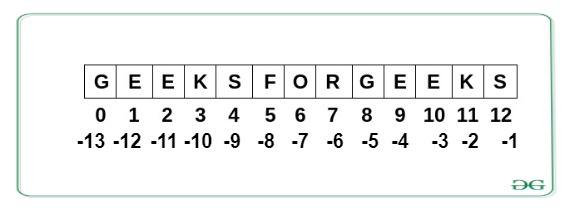
문자열에 포함된 모든 문자는 인덱스(index)라 불리는 고유번호를 부여받는다. 일종의 순서 개념이며, 왼편에 위치한 문자가 오른편에 위치한 문자보다 빠른 번호를 부여받는다.
인덱스는 문자열 왼편에서부터 0, 1, 2, 등으로 시작한다. 즉, 문자열의 가장 왼편에 위치한 문자가 0번, 그 오른편이 1번, 그 다음 오른편 2번, 등등으로 진행한다. 인덱스는 오른편에서부터 시작할 수도 있다. 이때는, 문자열의 가장 오른편에 위치한 문자가 -1번, 그 왼편이 -2번, 그 다음 왼편이 -3번, 등으로 진행한다.
예를 들어, 아래 그림은 'GEEKSFORGEEKS' 문자열의 인덱스를 보여준다.
슬라이싱¶
소스코드에 부분문자열로 포함된 문자열 '5.17'의 위치를 파악하려면
첫째 문자인 '5'의 인덱스를 확인하면 된다.
그런데 어떻게 소스코드 문자열에서 '5'의 인덱스를 알아낼 것인가가 문제이다.
page_text가 가리키는 문자열은 그렇게 길지는 않다.
아래 그림처럼 <html 부터 0, 1, 2, 3, 4, ... 등으로 인덱스를 세어볼 수 있다.

|
실제로 위와같이 세어보면 문자 '5'의 인덱스가 234임을 알 수 있다.
그리고 그곳에서부터 네 개의 문자를 읽으면 그게 바로 가격 정보가 된다.
주의: 점도 하나의 문자이다. 따라서 '5.17'에 포함된 문자는 네 개이다.
234번 인덱스 값부터 시작해서 네 개의 문자를 확인하려면 234번, 235번, 236번, 237번 인덱스의 값들을 추출하면 된다. 이를 위해 슬라이싱(slicing) 도구를 활용하며, 아래와 같이 실행한다.
page_text[234:238]
주의: 아래 실행 결과는 '5.17'과 다를 수 있음에 주의하라.
커피 원두 가격은 웹페이지에 접속하는 시점에 따라 달라지기 때문이다.
슬라이싱은 두 개의 인덱스로 지정된 구간에 위치한 문자들을 추출하여 새로운 문자열로 내준다.
앞서 사용한 구간 [234:238]은 234부터, 237까지의 인덱스 구간을 가리킨다.
주의: 구간 끝을 가리키는 인덱스 이전까지 추출함에 주의하라.
수동 카운팅의 문제¶
그런데 위와 같이 수동으로 인덱스를 확인하는 방식엔 다음과 같은 문제가 있다.
- 셈이 틀릴 수 있다.
- 문자열이 길 경우 셈 자체가 불가능할 수 있다.
- 문자열이 조금만 변경되어도 새로 처음부터 세어야 하기 때문에 경우에 따라 재활용이 불가능하다.
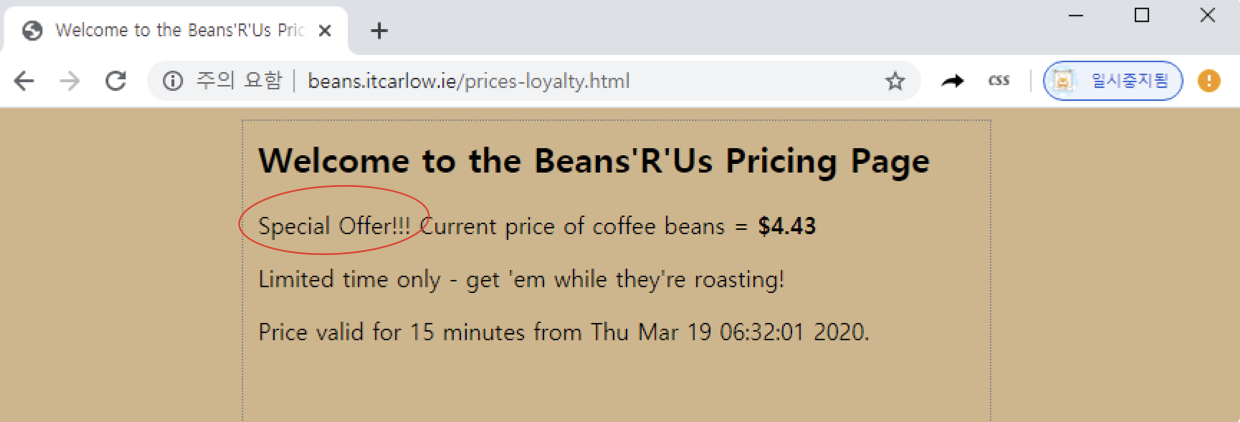
예를 들어, 주요 고객에게만 제공하는 좀 더 저렴한 커피 원두 가격 정보를 전달하는 아래 사이트에 동일한 프로그램을 적용하면 엉뚱한 결과를 얻게 된다.
http://beans.itcarlow.ie/prices-loyalty.html
주의: 위 주소가 작동하지 않을 경우 아래 주소를 대신 사용할 수 있다. 아래 주소 역시 고정된 내용을 담고 있는 하나의 웹페이지이다.
https://formal.hknu.ac.kr/lectures/HFProg/prices-loyalty.html
|
import urllib.request
price_url = "http://beans.itcarlow.ie/prices-loyalty.html"
price_page = urllib.request.urlopen(price_url)
page_text = price_page.read().decode("utf8")
print(page_text[234:238])
아래 그림에서 확인할 수 있듯이 234번 인덱스의 위치가 가격이 나오지 전으로 바뀌었다. 실제로 위 웹페이지에서 볼 수 있듯이 'Special Offer!!!' 란 표현이 추가되어 가격 정보의 인덱스가 뒤로 밀렸다.

|
find 메서드 활용¶
수동으로 인덱스를 확인하는 방법의 한계를 극복하기 위해
여기서는 find라는 문자열 메소드를 도구로 사용할 수 있다.
즉, find는 문자열에만 적용할 수 있는 함수이다.
다시 원래의 질문으로 돌아가서 어떻게 가격 정보가 시작하는 곳의 인덱스를 구할 수 있는지 생각해보자.
원하는 인덱스를 특징지울 수 있는 무언가를 찾아야 한다.
예를 들어, 가격 정보는 '>$' 라는 문자열 바로 다음부터 시작한다는 특징을 이용한다.

|
즉, 문자열 '>$'가 page_text에 할당된 문자열의 어느 위치에서 시작하는지를 알아내기만 하면 된다.
그리고 이 정보는 바로 find 메소드가 찾아준다.
앞서 설명하였듯이 메서드는 특정 자료형의 값(객체)에 대해서만 사용된다.
따라서 일반 함수와는 달리 항상 지정된 자료형의 값 뒤에 점으로 구분되어 따라온다.
예를 들어, 문자열 'Hello Python!'에서 사용된 부분문자열 'Python'이
위치한 곳의 인덱스, 즉 P의 인덱스는 아래와 같은 형식으로 형식으로 확인한다.
'Hello Python'.find('Python')
실제로 'Hello Python'에서 'P'의 인덱스는 6이다.
'Hello'와 'Python' 사이에 공백 문자가 있음에 주의하라.
이제 page_text 변수가 가리키는 문자열에서 '>$'가 시작하는 위치의
인덱스는 아래와 같이 확인하면 된다.
page_text.find('>$')
즉, 249번 인덱스 위치에서부터 '>$'가 시작한다는 의미이다.
따라서 그보다 2보다 큰 251번 인덱스에서 가격 정보가 시작한다는 것을 알게 되었다.
따라서 가격 정보를 아래와 같이 알아낼 수 있다.
주의: 249, 251과 같은 구체적인 숫자를 전혀 사용할 필요가 없다.
find 메소드로 알아낸 정보를 변수에 할당해서 사용하면 되기 때문이다.
price_location = page_text.find('>$') + 2
bean_price = page_text[price_location : price_location + 4]
print(bean_price)
이렇게 find 메소드를 활용하면 웹페이지가 조금 변경된다 하더라도 동일한 프로그램을 이용하여 가격정보를 얻어낼 수 있다.
bean_price 변수에 저장된 커피 원두의 가격정보는
웹페이지 소스코드의 부분문자열이다.
거기에 ' 달러'라는 문자열을 이어붙이면
앞서 본 것처럼 가격 정보라는 사실을 명확하게 전달할 수 있다.
두 문자열을 이어붙이는 연산자는 덧셈 기호(+)를 사용한다.
- 커피 원두콩 가격 정보 사이트(일반고객용)
import urllib.request
price_url = "http://beans.itcarlow.ie/prices.html"
price_page = urllib.request.urlopen(price_url)
page_text = price_page.read().decode("utf8")
price_location = page_text.find('>$') + 2
bean_price = page_text[price_location : price_location + 4]
# 문자 이어 붙이기에 주의
print(bean_price + ' 달러')
- 커피 원두콩 가격 정보 사이트(주요고객용)
import urllib.request
price_url = "http://beans.itcarlow.ie/prices-loyalty.html"
price_page = urllib.request.urlopen(price_url)
page_text = price_page.read().decode("utf8")
price_location = page_text.find('>$') + 2
bean_price = page_text[price_location : price_location + 4]
# 문자 이어 붙이기에 주의
print(bean_price + ' 달러')
커피 원두 가격 정보 활용¶
지금까지 배운 내용을 이용하여 커피 원두 가격이 기준가인 6.0달러 이상이면 매장의 아메리카노 가격을 올리고, 그렇지 않으면 가격을 그대로 유지하는 것을 실행하도록 하는 코드를 작성하면 다음과 같다.
가격 확인은 30초에 한 번 하는 것으로 한다. 이렇게 간격을 두지 않으면 1초에 수만, 수십만번 가격 확인을 하게 되어 웹서버에 많은 부담을 준다.
주의: 이런 식으로 특정 웹페이지에 많을 부담을 주어 웹서버를 공격하는 것을 DDos 공격, 즉, 분산 서비스 거부 공격(Distributed denial-of-service attack)이라 부른다.
프로그램 구상하기¶
일정 시간을 두고 반복적으로 가격을 확인해야 한다.
먼저, 일정 시간동안 프로그램의 실행을 멈추는 기능도 필요하며,
while 반복문을 사용하여 가격 확인을 반복적으로 실행한다.
while 명령문의 조건식과 본체에 사용될 명령문은 다음과 같다.
- 조건식: 확인된 가격이 기준가보다 낮은가를 판단한다.
- 본체 명령문:
- 일정 시간동안 프로그램 실행을 멈춘다.
- 웹페이지 서버에 접속해서 가격 정보를 확인한다.
프로그램 구현하기¶
프로그램 실행 멈추기¶
앞서 구상한대로 프로그램을 구현하려면 '일정 시간동안 프로그램 실행을 멈추게 하는 도구'가
필요하다. 이 목적을 위해 파이썬은 time 모듈에 sleep 함수를 제공한다.
sleep 함수는 지정된 시간(초 단위)동안 프로그램의 실행을 멈추게 하여,
시차를 두고 일을 진행하고 할 때 유용하게 사용된다.
time 모듈은 시간과 관련된 많은 함수들을 도구로 제공한다.
가장 많이 사용되는 time 모듈 함수들은 다음과 같다.
time.clock
time.daylight
time.gmtime
time.localtime
time.sleep
time.time
time.timezone
함수의 이름만 보더라도 함수의 기능을 어느 정도 추정할 수 있다.
추천: 파이썬 프로그래밍 입문서: 시간 다루기에서
time처럼 시간과 날짜와 관련된 파이썬 모듈과 함수에 대한 보다 자세한 설명과
사용 예제를 확인할 수 있다.
가격 정보 반복 확인¶
웹페이지 서버에 접속해서 가격 정보를 확인하는 일은
앞서 살펴본 코드와 동일하며, 거의 그대로 while 반복문의 본체로 사용할 수 있다.
앞서 설명한 구상대로 구현하면 다음과 같다.
주의: 기준가를 너무 높이 지정하면 아래 프로그램 실행이 오래 걸리거나 멈추지 않을 수도 있다. 또한 앞서 언급한 대체 웹페이지 주소를 사용할 경우 가격 변동이 없기 때문에 아래 프로그램 실행은 멈추지 않을 것이다.
import urllib.request
import time
price_basis = 6.0 # 기준가
bean_price = 5.0 # while 문이 작동하도록 임의로 지정된 현재 원두 가격
price_url = "http://beans.itcarlow.ie/prices.html"
while bean_price < price_basis: # 기준가보다 커질 때까지 가격 확인
# 30초 기다리기
time.sleep(30)
price_page = urllib.request.urlopen(price_url)
page_text = price_page.read().decode("utf8")
price_location = page_text.find('>$') + 2
# float로 변환해서 원두 가격 업데이트
bean_price = float(page_text[price_location : price_location + 4])
# 확인된 가격 보여주기
print("현재 가격:", bean_price)
# 기준가보다 높을 때 가격 인상 권유
print("커피 원두 현재 가격이", bean_price, "입니다. 아메리카노 가격을 인상하세요!")
추가 자료¶
문자열에 대한 보다 자세한 설명은 기본 자료형: 문자열에서 확인할 수 있다.
연습문제¶
커피 원두 가격을 확인하여 가격과 확인 시간을 함께 아래와 같은 형식으로 보여주는 프로그램을 작성하라.
Tue Mar 17 18:21:01 2020, $5.17커피 원두 가격이 기준가인 4.74달러 이하이면 커피 원두를 100kg 그램 구입하라고 안내하면서 구입비용도 계산해주는 프로그램을 작성하라. 가격 확인은 30초에 한 번 하는 것으로 한다.
- 사용자가 "지금 몇 시야?" 라고 물어보면 현재 시각을 '몇시 몇분 몇초 입니다'
형식으로 화면에 출력하는 프로그램을 구현하라.
(힌트: 파이썬 프로그래밍 입문서: 시간 다루기에서 적절한 도구를 찾아 활용하라.)