기본 자료형: 문자열¶
Think Python의 8장 내용을 요약 및 수정한 내용입니다.
문자열이란?¶
문자열은 문자들을 나열하여 하나로 묶은 대상을 가리킨다.
쉽게 말해서 키보드를 이용하여 입력할 수 있는 모든 기호들의 조합이 문자열이다.
문자열들의 자료형은 str이며 string(스트링)의 약어이다.
문자열은 작은따옴표(') 또는 큰따옴표(")로 감싸인다.
문자열 자료형은 모든 프로그래밍 언어에서 기본으로 제공될 정도로,
프로그래밍 언어의 핵심 요소이다.
주의: 작은따옴표와 큰따옴표를 혼합하여 문자열을 감싸면 오류가 발생한다.
여러 개의 문자들을 나열했다는 의미에서, 문자열 자료형을 서열 또는 시퀀스(sequence) 자료형의 일종으로 간주한다. 또한 여러 개의 값을 하나로 묶어서 다룬다는 의미로 모음(collection) 자료형으로 불리기도 한다.
참고:
시퀀스 또는 모음 자료형에는 문자열 이외에
리스트(list), 튜플(tuple), 어레이(array) 자료형도 포함된다.
반면에 사전(딕셔너리, dictionary) 자료형 dict는
모음 자료형에 포함되지만 시퀀스 자료형은 아니다.
이유는 시퀀스 자료형은 포함된 항목들 사이에 순서 개념이 있어야 하기 때문인데,
파이썬의 사전 자료형에는 순서 개념이 없다.
특수 문자¶
따옴표¶
따옴표가 포함된 아래 문장을 문자열로 사용하고자 한다.
opentutorial's "lectures" are great.
그런데 위 문장을 작은따옴표나 큰따옴표로 감싸면 구문 오류(SyntaxError)가 발생한다.
print("opentutorial's "lectures" are great.")
print('opentutorial's "lectures" are great.')
이유는 위 문장에 작은따옴표와 큰따옴표 모두 포함되어 있는데
따옴표가 문자열 자료형을 만드는 특수한 역할을 수행하기 때문이다.
해결책은 아래와 같이 따옴표 앞에 백슬래시(\, backslash) 기호를 붙혀서
따옴표의 특수 역할을 해제(escape)하는 것이다.
그런데 작은 또는 큰따옴표 중에 사용하는 것에 따라 백슬래시 사용이 조금씩 달라질 수 있다. 예를 들어, 아래는 큰따옴표로 감싸기에 작은따옴표는 그냥 두어도 된다.
print("opentutorial's \"lectures\" are great.")
반면에 아래는 작은따옴표로 감싸기에 큰따옴표는 그냥 두어도 된다.
print('opentutorial\'s "lectures" are great.')
물론 문자열에 포함된 모든 따옴표는 해제시키는 것이 다루기 편할 수도 있다.
print("opentutorial\'s \"lectures\" are great.")
print('opentutorial\'s \"lectures\" are great.')
백슬래시의 특수 기능¶
앞서 살펴보았듯이 백슬래시(\) 또한 특수 기능을 해제시키는 특수 기능을 갖는다.
이와 더불어 다른 특수기능도 갖고 있다.
'\n'은 줄바꿈을 의미한다.
print("Hello\n World")
그리고 '\t'은 탭(tab)키를 한 번 누른 것에 해당한다.
탭 키 한 번은 보통 스페이스 키 네 번 또는 두 번 누른 것과 동일하며,
사용하는 편집기에 따라 크기가 다를 수 있다.
print("Hello\tWorld")
따라서 백슬래시 자체를 문자열에 포함하면 기대와 다르게 작동한다.
print("Good\night")
따라서 백슬래시를 문자열에 포함시키려면 아래와 같이 해야 한다.
print("Hello\\n World")
print("Hello\\t World")
print("Good\\night")
그런데 이렇게 하면 백슬래시를 경우에 따라 너무 많이 사용하게 되어
혼라스러워질 수 있다.
예를 들어, '\\'처럼 백슬래시 두 개를 연속을 출력하고 한다면 아래와 같이 해야 한다.
print("\\\\")
그리고 아래와 같은 경우는 오류가 자주 발생한다.
print("\\\")
순수 문자열(raw string)¶
이런 혼란을 방지하면서 보다 쉽게 특수문자를 다루는 방법이 있다. 바로 '가공되지 않은, 날 거의'의 의미를 갖는 'raw' 단어의 첫 글자인 'r'을 문자열 앞에 두면 특수 기능이 사라진다. 이런 문자열을 특수 기능이 없는 문자들의 나열이라는 의미에서 순수 문자열(raw string)이라 부른다.
print(r"Hello\n World")
print(r"Hello\t World")
print(r"Good\night")
print(r"\\")
서식 지원¶
문자열을 주어진 그대로가 아닌 지정된 서식에 맞추어 다양한 형식으로 출력할 수 있다. 예를 들어, 문자열 내부에 변수와 같이 변하는 값이 반영된 문자열을 출력할 수 있으며, 자릿수 등을 지정하여 보다 통일된 형식으로 숫자들을 출력할 수 있다. 이와 같이 서식이 지원되는 문자열을 다루는 방식은 여러 가지 있다. 여기서는 파이썬 3.6 버전부터 지원되는 f-문자열(f-string) 방식만을 소개하며, 이후 모든 서식 지원 문자열을 f-문자열 방식으로만 사용할 것이다.
기본 서식¶
변수를 사용하여 보다 탄력적인 문자열을 출력하는 기본 방식은 아래와 같다.
name = '홍길동'
age = 19
print(f'{name}의 나이는 {age}살입니다.')
변수의 값을 업데이트 하면 업데이트 된 값이 문자열에 반영된다.
name = '성춘향'
age = 16
print(f'{name}의 나이는 {age}살입니다.')
연산 결과도 사용가능하다.
bags = 3
books_in_bag = 12
print(f'총 {bags * books_in_bag}권의 책이 있다.')
함수의 리턴값도 사용가능하다.
aNum = -3
print(f'{aNum}의 절댓값은 {abs(aNum)}입니다.')
순수 문자열과의 조합¶
인용부호, 백슬래시 등 특수 기능을 갖는 문자들의 기능을 해제하려면 백슬래시를 사용하면 된다.
aLanguage = '파이썬'
print(f'{aLanguage}는 \'아주 훌륭한\' 언어이다.')
순수 문자열(raw string)을 지원하는 방식과 혼합하여 사용하면 보다 자연스럽게 특수 문자들을 다룰 수 있다. 예를 들어, 아래와 같이 하면 백스래시 자체도 단순한 문자로 취급한다.
aLanguage = '파이썬'
print(fr'{aLanguage}는 \'아주 훌륭한\' 언어이다.')
물론 아래와 같이 하면 오류가 발생한다. 이유는 문자열의 시작과 끝을 구분하는 기준이 혼동되기 때문이다.
aLanguage = '파이썬'
print(fr'{aLanguage}는 '아주 훌륭한' 언어이다.')
부동 소수점 출력 자릿수 지정¶
부동 소수점을 출력할 때 다음 두 가지 사항을 지정할 수 있다.
- 숫자들을 동일한 크기의 영역에 오른편으로 정렬시키기
- 출력될 소수점 이하 숫자들의 개수, 즉, 출력 정밀도 지정하기.
- 빈칸을 0으로 채우기
아래 예제들을 통해 사용법을 확인할 수 있다.
aFloat = 12.3
print(f'{aFloat:.2f}')
print(f'{aFloat:.5f}')
print(f'{aFloat:10.2f}')
print(f'{aFloat:10.5f}')
print(f'{aFloat:010.2f}')
print(f'{aFloat:010.5f}')
정수 출력 자릿수 지정¶
정수는 소수점을 사용하지 않기때문에 출력되는 영역의 크기만 지정하면 자동으로 오른쪽으로 정렬된다. 빈칸을 0으로 채우는 방법은 동일하다.
for x in range(1, 11):
print(f'{x:02} {x*x:3} {x*x*x:4}')
일반 문자열 오른쪽 정렬¶
일반 문자열은 기본적으로 왼쪽으로 정렬되어 출력된다.
str1 = 'a'
str2 = 'ab'
str3 = 'abc'
str4 = 'abcd'
print(f'{str1}')
print(f'{str2}')
print(f'{str3}')
print(f'{str4}')
그런데 오른쪽으로 정렬해서 출력하려면 출력 영역의 크기를 지정한 후 > 기호를 함께 사용하면 된다.
str1 = 'a'
str2 = 'ab'
str3 = 'abc'
str4 = 'abcd'
print(f'{str1:>4}')
print(f'{str2:>4}')
print(f'{str3:>4}')
print(f'{str4:>4}')
진법 다루기¶
숫자들은 기본적으로 십진법으로 표기된다. 이를 16진법, 8진법, 또는 과학적 표기법 등으로 변환하여 출력할 수 있다.
a = 2020
# 16진법
print(f"{a}은 16진법으로 {a:x}이다.")
# 8진법
print(f"{a}은 8진법으로 {a:o}이다.")
# 과학적 표기법
print(f"{a}를 과학적 표기법으로 {a:e}이다.")
인덱스¶
문자열에 포함된 모든 문자는 인덱스(index)라 불리는 고유번호를 부여받는다. 일종의 순서 개념이며, 왼편에 위치한 문자가 오른편에 위치한 문자보다 빠른 번호를 부여받는다.
인덱스는 문자열 왼편에서부터 0, 1, 2, 등으로 시작한다. 즉, 문자열의 가장 왼편에 위치한 문자가 0번, 그 오른편이 1번, 그 다음 오른편 2번, 등등으로 진행한다. 인덱스는 오른편에서부터 시작할 수도 있다. 이때는, 문자열의 가장 오른편에 위치한 문자가 -1번, 그 왼편이 -2번, 그 다음 왼편이 -3번, 등으로 진행한다.
예를 들어, 아래 그림은 'GEEKSFORGEEKS' 문자열의 인덱스를 보여준다.
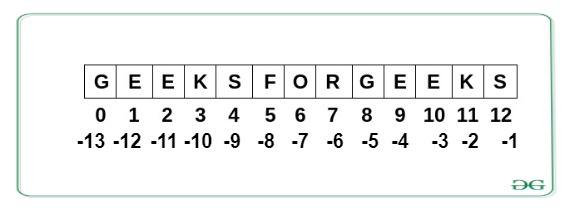
참조: 인덱스는 어떤 기준으로부터 몇 번째에 해당하는가를 나타내는 오프셋(offset)이라는 컴퓨터 전문용어의 특수한 사례이다. 여기서는 오프셋 개념이 다양한 경우에 사용된다는 점만 기억해두면 좋다.
인덱싱: 대괄호 연산자 []¶
특정 인덱스에 해당하는 문자에 접근하려면 대괄호([])를 이용한다.
fruit = 'orange'
fruit에 할당된 문자열 orange의 첫째 문자는 fruit[0]이다.
first_letter = fruit[0]
print(first_letter)
'n'은 왼편에서 넷 째 자리에 위치한다.
따라서 인덱스는 3를 사용한다.
fruit[3]
주의: 정수만 인덱스로 사용될 수 있다. 예를 들어, 1.5번 인덱스는 존재하지 않는다.
letter = fruit[1.5]
정수를 가리키는 모든 표현식을 인덱스로 사용할 수 있다.
i = 2
fruit[i]
fruit[i+1]
인덱스를 거꾸로 세면 가장 오른편에 위차한 문자의 인덱스는 -1이다.
fruit[-1]
fruit[-2]
문자열의 길이¶
문자열의 길이 문자열에 포함된 항목의 개수를 의미하며,
len 함수를 이용하여 구할 수 있다.
예를 들어, 'orange'는 6개의 문자를 포함한다.
# fruit = 'orange'
len(fruit)
주의:
len 함수는 문자열 자료형의 메서드가 아니며,
리스트, 튜플 등 다른 시퀀스 자료형에도 활용할 수 있다.
인덱스와 len 함수¶
인덱스가 0부터 시작하기 때문에 문자열에 포함된 마지막 문자를 가리키는 인덱스는
len 함수가 되돌려 주는 값보다 1이 작다.
예를 들어, 'orange'의 마지막 알파벳인 'e'의 인덱스는 6이 아니라 5이다.
length = len(fruit)
'orange'[length]
대신에 다음과 같이 해야 한다.
length = len(fruit)
'orange'[length-1]
슬라이싱¶
문자열의 일부분을 선택하는 방법을 슬라이싱(slicing) 이라 부른다.
예를 들어, '파이썬 너무 좋아요'라는 문자열에서 '파이썬'를 추출하려면
0번 인덱스부터 2번 인덱스까지 세 개의 문자를 추출하면 된다.
iLikePython = '파이썬 너무 좋아요'
print(iLikePython[0:3])
주의:
like_python[0:3] 이 아님에 주의한다.
슬라이싱의 구간을 적을 때 끝나는 인덱스는 마지막 문자의 인덱스보다 1이 큰 숫자를 사용한다.
'너무'를 원한다면 4번, 5번 인덱스의 문자를 추출해야 한다.
주의: '파이썬'과 '너무' 사이에 공백(스페이스)가 있으며, 공백 또한 하나의 문자로 취급된다.
print(iLikePython[4:6])
슬라이싱 활용 예제¶
콜론(:) 앞에 있는 첫째 인덱스를 생략하면, 슬라이스는 문자열의 처음부터 시작한다.
print(fruit[:3])
print(iLikePython[:5])
반면에 콜론(:) 뒤에 있는 둘째 인덱스를 생략하면, 슬라이스는 문자열의 끝까지를 의미한다.
fruit[3:]
print(iLikePython[5:])
콜론(:)만 사용하면 문자열 전체를 가리킨다.
fruit[:]
iLikePython[:]
첫 번째 지수가 두 번째보다 크거나 같으면 결과는 빈 문자열('')이 슬라이싱 된다.
fruit[3:3]
iLikePython[6:2]
스텝 슬라이싱¶
슬라이싱인 지정한 구간 내에 포함된 모든 부분문자열을 추출한다. 그런데 지정된 구간 내에서 일정한 거리를 두고 문자열을 추출할 수도 있다. 두 항목 사이의 거리는 스텝(step)으로 지정하며, 스텝은 둘째 콜론 다음에 위치한다. 스텝의 기본값은 1이며, 스텝이 1이 스텝은 생략할 수 있다.
예를 들어, 문자열 '0123456789'에서 홀수만 추출하고 할 때 다음과 같다.
numsUpTo10 = '0123456789'
numsUpTo10[0:10:2]
물론 다음과 같이 할 수도 있다.
numsUpTo10[::2]
이번엔 홀수만 추출해보자. 시작 인덱스를 0에서 1로 교체하면 된다.
numsUpTo10[1::2]
3의 배수만 추출할 수도 있다.
numsUpTo10[::3]
3보다 크면서 3으로 나눠 나머지가 2인 숫자들은?
numsUpTo10[3:9:2]
아니면
numsUpTo10[4::2]
역순으로 거리를 두면서 추출하는 것도 가능하다. 예를 들어, 홀수들만 역순으로 추출해 보자.
numsUpTo10[-1:: -2]
3과 7 사이의 짝수를 역순으로?
numsUpTo10[-3:2: -2]
빈 문자열¶
빈 문자열('')은 문자를 전혀 포함하지 않은 특수한 문자열이다.
빈 문자열('')과 공백 문자 한 개로 이루어진 문자열(' ')은 서로 다름에 주의해야 한다.
실제로, 빈 문자열의 길이는 0인 반면에, 공백 문자 한 개로 이루어진 문자열의 길이는 1이다.
len('')
len(' ')
문자열 다루기¶
인터넷 상에 존재하는 수 많은 정보들 중에서 중요한 정보를 적절한 형식으로 전달하는 일의 중요성을 누구나 인정할 것이다.
그런데 인터넷 상의 정보는 기본적으로 모두 문자열로 구성된다. 예를 들어, 검색할 때 문장(문자열)을 입력하면, 구글, 다음, 네이버 등의 검색엔진은 인터넷 상에 있는 수 많은 자료(문장, 즉 문자열, 사진, 동영상 등) 중에서 원하는 정보를 담고 있는 적절한 자료를 찾아 전달한다.
참조: 사진, 동영상 등도 숫자 기호를 사용하는 문자열들로 이루어진 특수한 구조의 자료로 처리한다.
따라서 문자열을 비교하고, 분석하고, 조작하는 기술은 매우 중요하다. 앞서 다룬 인덱싱과 슬라이싱이 문자열을 다루는 가장 기본적인 함수들이다. 아래에서 문자열 다루는 다양한 도구(함수)들과 연산자들을 살펴본다.
문자열 이어붙이기¶
문자열 두 개를 이어붙이려면 덧셈 기호를 사용한다.
'hello, ' + 'python'
문자열을 복제하여 이어붙이려면 정수와의 곱셈을 사용한다.
'hi!' * 3
3 * 'hi! '
하지만 문자열 끼리의 곱셈은 정의되어 있지 않다. 그리로 문자열과 관련한 나눗셈은 아예 없다.
'hi' * 'python'
하지만 문자열과 숫자와의 덧셈과 비교 등은 허용되지 않는다. 서로 자료형이 다르기 때문이다. 예를 들어 아래 코드는 타입 오류를 발생시킨다. 비교하는 두 값의 자료형이 다르기 때문이다.
'4.35' > 2.1
이전에 정수 모양의 문자열을 int 함수를 이용하여 정수로 변환하였듯이
실수 모양의 문자열을 float 함수를 활용하여 부동소수점 자료형, 즉 float 자료형으로
변환할 수 있다.
float('4.35') > 2.1
int 함수가 정수 모양의 문자열만 다룰 수 있는 것처럼,
float 함수 또한 실수 모양의 문자열에만 작동하며
다른 모양의 문자열이 인자로 들어오면 오류가 발생한다.
int('4.2') > 2.1
float('4.2g') > 2.1
in 연산자¶
in 연산자는 부분문자열 여부를 판단한다.
예를 들어, 'an'은 'orange'의 부분문자열이다.
'an' in 'orange'
반면에 'seed'는 'orange'의 부분문자열이 아니다.
'seed' in 'orange'
동치성 비교¶
임의의 두 값의 동치성 비교는 == 또는 != 연산자를 사용하며, 문자열의 경우도 동일하다.
'orange' == 'apple'
'orange' != 'apple'
크기 비교¶
문자열들 사이의 크기 비교는 산전식 순서를 따른다. 즉, 알파벳 순서를 중요시 여긴다.
word = 'banana'
if word < 'orange':
print('Your word, ' + word + ', comes before orange.')
elif word > 'orange':
print('Your word, ' + word + ', comes after orange.')
else:
print('All right, oranges.')
영어 알파벳의 경우 대문자가 소문자보다 작다고 판단한다.
'Pineapple' < 'orange'
따라서 문자열을 다룰 때 소문자 또는 대문자로 통일시킨 후에 비교를 해야 사전식으로 제대로 정렬할 수 있다.
문자열을 모두 소문자로 바꾸려면 lower 라는 문자열 메서드를 사용한다.
'Pineapple'.lower() < 'orange'.lower()
메서드와 함수¶
문자열을 다루기 위해 문자열 메서드를 잘 활용해야 한다. 따라서 문자열 활용법을 더 이야기하기 전에 메서드와 함수의 정의와 차이점을 살펴본다.
함수가 하는 일은 기본적으로 매우 단순하다.
어떤 값들이 인자로 주어지면 그 값들을 적절히 이용하여 특정 값을 계산한 후 리턴값으로 내준다.
예를 들어, 절댓값을 계산하는 함수 abs는 실수를 입력받아,
그 값의 절댓값을 내준다.
abs(-3.3)
그리고 type 함수는 임의의 값을 입력 받아 해당 값의 자료형을 내준다.
type(abs(-3.3))
심지어 함수도 자료형을 갖는다.
type(abs)
함수는 임의의 값을 인자로 받는다. 하지만 함수마다 다룰 수 있는 값들의 자료형이 존재하며, 다룰 수 없는 자료형의 값이 인자로 사용되면 오류가 발생한다.
예를 들어, type 함수는 모든 자료형의 값을 다룰 수 있다.
즉, 임의의 값의 자료형을 확인할 수 있다.
반면에, abs 함수는 정수와 실수는 다루지만, 다음과 같이 문자열을
인자로 사용하면 오류가 발생한다.
abs('-3.3')
이렇듯, 파이썬 함수는 임의의 값에 적용될 수 있지만, 인자의 자료형을 파이썬 해석기가 파악해서 적용가능 여부를 판단한다. 즉, 처음부터 인자의 자료형을 지정하거나 확인하는 게 아니라 프로그램을 실행하는 도중에 사용되는 함수 인자들의 자료형을 확인한다는 의미이다.
메서드 실행¶
함수와 달리, 메서드는 특정 자료형과 함께 사용된다.
즉, 메서드 또한 함수이지만 사용할 때 제한사항이 따른다는 의미이다.
예를 들어, 문자들을 모두 대문자로 바꾸는 upper 메서드를
아래와 같이 사용하면 upper 가 정의되어 있지 않다는 오류가 발생한다.
참고: 메서드의 작동방식은 이후에 클래스를 다룰 때 보다 자세히 설명한다.
upper('orange')
orange 문자열에 포함된 문자 전부를 대문자로 바꾸려면 아래와 같이 해야 한다.
'orange'.upper()
또한 upper 메서드는 문자열과 함께 사용되며, 다른 자료형과 함께 사용하면 오류가 발생한다.
117.upper()
인자 사용법¶
메서드도 일반 함수처럼 인자를 받을 수 있다.
특정자료형값.메서드이름(인자1, 인자2, ..., 인자n)iLikePython = 'I like Python.'
replace 메서드는 치환 대상과 대입할 문자열을 인자로 사용한다.
iLikePython.replace('너무', '최고로')
인자가 필요 없더라도 괄호 열고닫기는 반드시 사용해야 한다.
iLikePython.split()
문자열 메서드¶
앞서 살펴본 lower, upper 이외에 문자열과 관련된 메서드는 매우 많다.
여기서는 가장 많이 사용되는 메서드 몇 개를 소개하고자 한다.
stripsplitreplaceupperlowercapitalizetitlestartswithendswithfind
예제를 통해 각 메서드의 활용법을 간략하게 확인한다.
먼저 week_days 변수에 요일들을 저장한다.
week_days = " Mon, Tue, Wed, Thu, Fri, Sat, Sun. "
strip 메서드¶
메서드 인자로 임의의 문자열을 받는다. 그러면 주어진 문자열의 양 끝에서 인자로 들어온 문자열에 포함된 모든 문자를 삭제하여 새로운 문자열을 생성한다. 예를 들어, 문자열 양끝에 있는 스페이스를 삭제하고자 할 경우 아래와 같이 실행한다.
week_days.strip(" ")
이는 strip() 메서드를 인자 없이 호출하는 경우와 동일하다.
week_days.strip()
그런데 점(.)까지 Sun.에서 삭제하려면 공백과 점으로 구성된 문자열
'. '를 인자로 사용해야 한다.
week_days.strip(" .")
. nM을 인자로 사용하면 다음처럼 작동하는 것을 이해할 수 있어야 한다.
week_days.strip(". nM")
split 메서드¶
지정된 부분문자열을 기준으로 문자열을 쪼개어 문자열들의 리스트를 생성한다. 리스트 자료형은 여러 개의 값들을 리스트로 묶은 자료형이다. 이후에 자세히 다룬다.
아래 예제는 ", ", 즉 콤마와 스페이스를 기준으로 문자열을 쪼갠다.
week_days.split(", ")
두 개 이상의 메서드를 조합해서 활용할 수도 있다.
예를 들어, strip() 메서드를 먼저 실행한 다음에 그 결과에 split() 메서드를 실행하면
좀 더 산뜻한 결과를 얻을 수 있다.
week_days.strip(". ").split(", ")
위는 아래와 동일한 일을 수행한 결과이다.
stripped_week_days = week_days.strip('. ')
stripped_week_days.split(', ')
replace 메서드¶
부분문자열을 다른 문자열로 대체하는 방식으로 새로운 문자열을 생성한다.
예를 들어, " Mon"을 "Mon"으로 대체할 경우 아래와 같이 실행한다.
week_days.replace(" Mon", "Mon")
upper 메서드¶
모든 문자를 대문자로 변환시켜 새로운 문자열을 생성한다.
week_days.upper()
week_days.strip('. ').upper()
lower 메서드¶
모든 문자를 소문자로 변환시켜 새로운 문자열을 생성한다.
week_days.strip('. ').lower()
week_days.strip('. ').lower().split(", ")
capitalize 메서드¶
제일 첫 문자는 대문자로, 나머지는 소문자로 변환시켜 새로운 문자열을 생성한다. 아래 예제는 모든 게 소문자로 변환되었다. 이유는 첫 문자가 스페이스이기 때문이다.
week_days.capitalize()
따라서 먼저 strip을 적용하면 첫 문자가 대문자로 바뀐다.
week_days.strip().capitalize()
title 메서드¶
각각의 단어의 첫 문자를 대문자로 변환시켜 새로운 문자열을 생성한다. 참조: 영문 책 제목의 타이틀에서 각 단어의 첫 알파벳이 대문자로 쓰여지는 경우가 많다.
week_days.title()
week_days.strip('. ').title()
startswith 메서드¶
문자열이 특정 문자열로 시작하는지 여부를 판단해준다.
week_days.startswith(" M")
week_days.strip().startswith(" M")
week_days.strip().startswith("Mo")
endswith 메서드¶
문자열이 특정 문자열로 끝나는지 여부를 판단해준다.
week_days.endswith("un. ")
week_days.endswith("Son. ")
count 메서드¶
문자열을 입력받으면 해당 문자열이 몇 번 나타나는지를 확인해서 리턴한다. 대소문자를 구분함에 주의하라.
week_days.count('on')
week_days.count('T')
week_days.count('Fri')
week_days.count(', ')
find 메서드¶
부분문자열이 시작하는 위치, 즉 인덱스를 알려준다. 부분문자열이 여러 군데 위치한다면 첫 위치의 인데를 내준다.
week_days.find(', ')
week_days.find('n, ')
부분문자열이 존재하지 않으면 -1을 내준다.
week_days.find('m, ')
수정 불가능성¶
파이썬의 문자열 자료형의 값들은 수정이 불가능하다.
앞서 week_days에 할당된 문자열에 다양한 메서드를 적용하여 새로운 문자열을 생성하였지만
week_days에 할당된 문자열 자체는 전혀 변하지 않았음을 아래와 같이 확인할 수 있다.
week_days
따라서 주어진 문자열을 이용하여 새로운 문자열을 생성하고 활용하려면 새로운 변수에 저장하여 활용해야 한다.
stripped_week_days = week_days.strip(' .')
stripped_week_days
물론 아래와 같이 지금까지 배운 기술을 (일부러 조금) 복잡하게 활용할 수도 있다.
stripped_week_days = 'Mon, ' + week_days[6:-2]
print(stripped_week_days)
연습문제¶
아래 코드를 수정하여
Qack대신에Quack가 출력되도록 하라.prefixes = 'JKLMNOPQ' suffix = 'ack' for letter in prefixes: print(letter + suffix)
(힌트:
if ... else ...명령문을 활용할 수 있다.)count라는 문자열 메서드의 활용예제를 3개 들어라.strip라는 문자열 메서드의 활용예제를 3개 들어라.
참조: https://www.dotnetperls.com/strip-pythonreplace라는 문자열 메서드의 활용예제를 3개 들어라.커피 원두 가격을 확인하여 가격과 확인 시간을 함께 아래와 같은 한글 형식으로 보여주는 프로그램을 작성하라.
2020년 3월 17일, 화요일, 저녁 6시 21분, 5.17달러(힌트: 영 단어와 한국 단어들 사이의 연결관계를 먼저 구현한다.)
- 사용자가 "지금 미국 뉴욕 현재시각 알려줘!" 라고 물어보면 뉴욕의 현재시각을 알려주는 프로그램을 구현하라.
(힌트: 문자열을 메서드와time모듈의 메서드를 적절하게 활용하라.)