기본 자료형: 파일¶
안내: Think Python 14장 내용을 번역 및 요약수정한 내용입니다.
지금까지 실행한 프로그램은 데이터를 일시적으로 생성하여 활용한다. 여기서 일시적이라 함은 프로그램이 종료되면 사용되었던 데이터가 사라진다는 의미다. 따라서 프로그램을 새로 시작하면 데이터를 새로 생성하여 활용하고, 종료되면 역시 사용했던 모든 데이터는 사라진다.
하지만 경우에 따라 사용할 또는 사용했던 데이터를 프로그램의 실행 및 종료에 상관 없이 오랫동안 보관하고자 할 필요가 있다. 여기서는 파일에 저장된 데이터를 활용하거나 사용된/생성된 데이터를 파일에 저장하는 가장 기초적인 방법을 소개한다.
파일 읽기¶
아래 링크에 있는 파일을 가지고 연습하고자 한다. 먼저 아래 주소에 있는 파일을 다운 받아서 파이썬 코딩을 실습하는 폴더에 저장한다.
http://thinkpython2.com/code/words.txt
여기서는 data라는 하위폴더에 words.txt라는 파일로 저장하는 방식은 두 가지이다.
- 첫째 방식: 위 링크를 눌러 해당 파일을 다운로드 한 후 현재 폴더에 위치한
data폴더에 저장한다. - 둘째 방식: 인터넷에서 정보구하기에서 사용했던 기법을 똑같이 사용할 수 있으며, 단순히 아래 코드를 실행하면 된다. 아래 코드에 사용된 명령문 설명은 이후 차차 설명될 것이다.
import urllib.request
import os
def myWget(dirPath, fileURL, fileName):
# dirPath 디렉토리 생성. 이미 존재하면 건너 뜀.
try:
os.mkdir(dirPath)
except FileExistsError:
pass
# 파일 저장 주소에서 파일 내용을 가져오기.
contents = urllib.request.urlopen(fileURL).read().decode("utf8")
# 가져온 파일 내용을 텍스트 파일로 저장하기.
# words.txt 파일이 이미 존재할 경우 새파일로 생성됨.
# 즉, 기존 파일 내용을 덮어 씀.
with open(dirPath+'/'+fileName, 'w') as f_out:
for line in contents:
f_out.write(line)
path = './data'
url = 'http://thinkpython2.com/code/words.txt'
fName = 'words.txt'
myWget(path, url, fName)
위 파일에는 그레이디 워드(Grady Ward)가 수집한 낱말 113,809개가 담겨 있다.
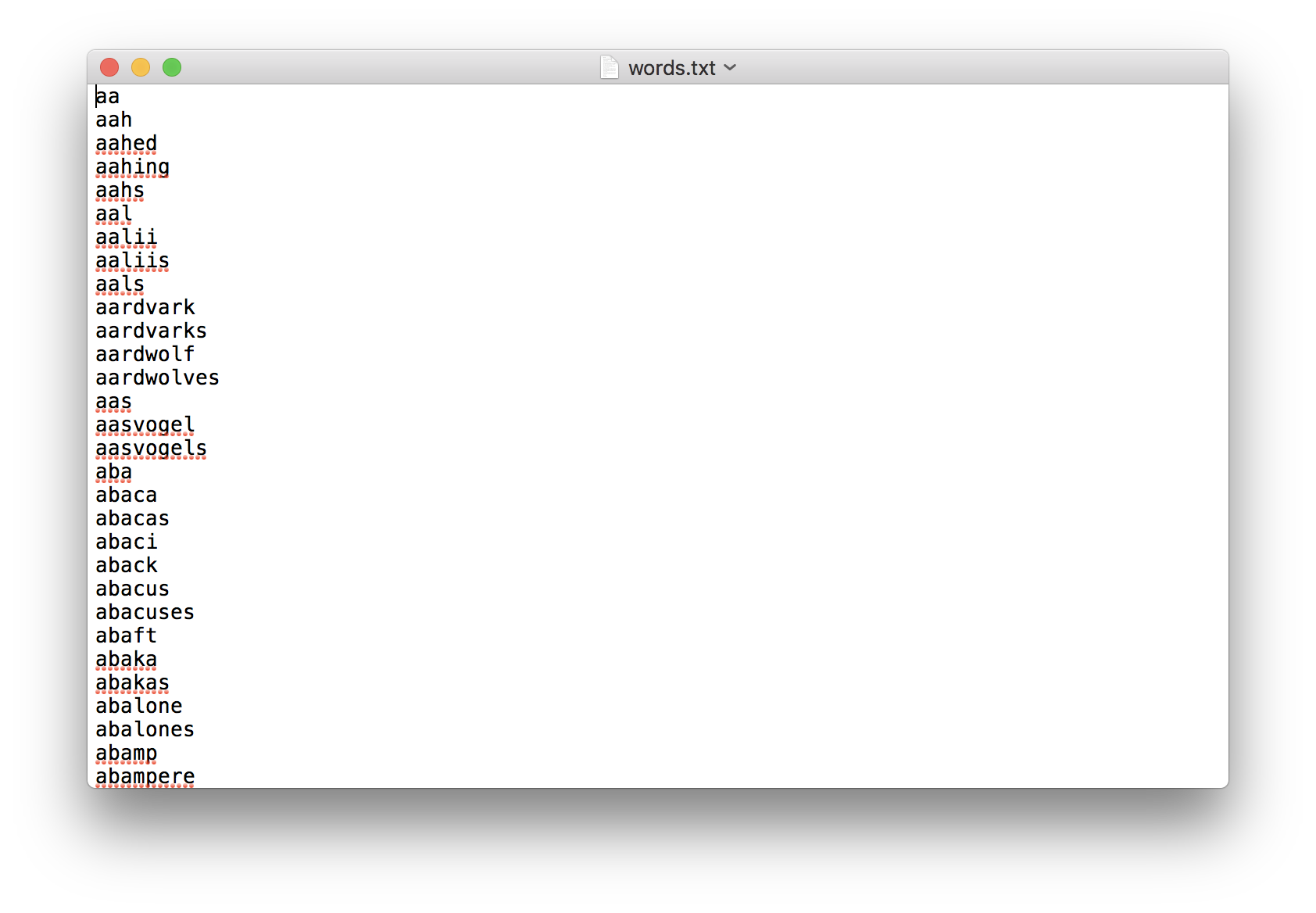
|
words.txt 파일을 파이썬으로 읽어 오자.
이를 위해 내장 함수인 open 함수를 아래와 같이 활용한다.
주의: ./data/words.txt에서 점(.)은 현재 폴더를 가리킨다.
따라서 ./data는 data가 현재 폴더의 하위폴더임을 의미한다.
f_in = open('./data/words.txt')
open 함수는 컴퓨터에 저장된 파일의 경로를 문자열 인자로 사용하여 파일 내용 뿐만 아니라
파일과 관련된 모든 정보를 가져와서 리턴값으로 되돌려 준다.
하지만 저장된 파일은 단순히 파일 내용 뿐만 아니라 파일의 크기, 작성 시간, 작성자, 수정 시간,
사용자 권한 등 다양한 정보도 함께 포함한다는
사실에 주의해야 한다.
open 함수의 리턴값은 파일과 관련된 모든 정보를 저장한 _io.TextIOWrapper라는 파일 클래스의 객체이다.
물론 클래스 이름을 기억할 필요는 없다.
type(f_in)
따라서 단순히 print 명령으로는 파일 내용을 확인할 수 없다.
print(f_in)
- 모드(mode)의 'r'은 이 파일이 읽기전용(read only)으로 열렸다는 것을 나타냄.
- 인코딩(encoding)이
UTF-8방식을 사용했음 확인할 수 있음.
파일 내용 한 줄씩 읽기¶
f_in 변수에 할당된 파일 객체의 내용을 readline 메소드를 활용하여 한 줄씩 확인할 수 있다.
첫째줄은 아래와 같다.
f_in.readline()
마지막 문자인 '\n'는 줄바꿈을 의미함에 주의하라.
이 기호가 있기에 위 그림에서처럼 각 단어가 다른 줄에 위치하는 것이다.
줄바꾸기 문자를 제거하면 보다 자연스럽게 출력할 수 있다.
이를 위해 strip 이라는 문자열 메소드를 활용하면 된다.
print(f_in.readline().strip())
readline 메서드는 실행될 때마다 이전에 읽어 준 다음 줄의 내용을 문자열로 내준다.
즉, readline 메소드는 몇 번째 줄까지 읽었는가를 오프셋(offset)이란 장치에
저장하는 방식으로 기억해둔다.
f_in.readline()
f_in.readline()
오프셋을 0으로 지정하면 다시 처음부터 읽는다.
이를 위해 seek 메서를 활용한다.
f_in.seek(0)
이제 다시 처음부터 일기 시작해야 한다.
f_in.readline()
f_in.readline()
f_in.readline()
파일 내용 전체 확인하기¶
파일 내용을 for 반복문을 이용하여 확인할 수 있다.
예를 들어, 아래 프로그램은 words.txt 파일에 저장된 모든 단어를 출력한다.
주의: 아래 코드를 실행하게 되면 113,809개의 단어들이 출력된다. 굳이 돌릴 것을 권하지는 않는다.
f_in = open('./data/words.txt')
for line in f_in:
word = line.strip()
print(word)
f_in.close()
하지만 아래 코드와 같이 읽는 단어의 개수를 제한하는 방식으로 맨 앞에 있는 몇 개의 단어를 확인할 수는 있다.
주의:
- 아래 코드는 다시 첫 단어부터 출력한다.
- 이유는
words.txt파일을 다시 읽으면서 오프셋이 0으로 초기화되기 때문이다.
아래 코드는 첫 10개의 단어를 읽는다.
f_in = open('./data/words.txt')
offsetNum = 0
for line in f_in:
if offsetNum < 10:
print(line.strip())
offsetNum += 1
else:
break
f_in.close()
줄번호를 표시하면 보다 알아보기 쉽다.
f_in = open('./data/words.txt')
offsetNum = 0
for line in f_in:
if offsetNum < 10:
print(f'{offsetNum}번: {line.strip()}')
offsetNum += 1
else:
break
f_in.close()
파일 닫기¶
마지막줄에서 사용된 close 메서드는 open 함수에 의해 열려진 파일을 닫는 역할을 수행한다.
즉, 파일 내용을 더 이상 들여다 볼 수 없다.
따라서 아래와 같이 다시 readlines 메서드를 실행하면 오류가 발생한다.
f_in.readlines()
파일을 열어 사용했으면 닫아주어야 한다. 그렇지 않으면 의도치 않게 파일이 손상될 수 있기 때문이다. 따라서 애초부터 지정된 일을 마친 후에 자동으로 파일을 닫도록 하는 것이 권장된다. 사용 방식은 다음과 같다.
with open('파일이름') as 파일변수:
명령문
예를 들어, 위 코드를 아래와 같이 작성해도 동일하게 작동한다.
with open('./data/words.txt') as f_in:
offsetNum = 0
for line in f_in:
if offsetNum < 10:
print(f'{offsetNum}번: {line.strip()}')
offsetNum += 1
else:
break
앞으로 위와 같은 방식을 선호해서 사용하고자 한다.
파일 내용 통째로 읽어오기¶
파일 내용 전체를 통재로 읽어오는 두 가지 방식이 있다.
readlines 메소드¶
파일 내용 전체를 리스트로 반환한다. 리스트의 항목은 각각의 줄에 담겨 있는 문자열이다.
예를 들어, words.txt의 경우 총 113,809개의 줄로 구성되어 있기에
113,809 개의 문자열로 구성된 리스트를 생성한다.
주의: readlines 메서드 역히 파일 내용을 한줄한줄 확인하면서
어디까지 확인하였는가를 오프셋 장치에 저장한다.
따라서 readlines 메서드의 실행이 종료되면 오프셋은 파일 내용의 끝을 가리킨다.
결국 readlines 메서드를 다시 사용하려면 seek 메서드를 사용하여
오프셋이 파일의 처음을 가리키도록 해야 한다.
with open('./data/words.txt') as f_in:
print(type(f_in.readlines()))
f_in.seek(0)
print(len(f_in.readlines()))
f_in.seek(0)
print(type(f_in.readlines()[0]))
read 메소드¶
파일에 저장된 내용 전체를 하나의 문자열로 리턴한다.
with open('./data/words.txt') as f_in:
print(type(f_in.read()))
파일 내용의 초반 내용 일부를 이용하기 위해 슬라이싱을 사용할 수 있다. 예를 들어, 아래 명령문은 문자열 맨 앞의 100개의 문자를 보여준다. 대략 처음 15줄에 해당한다.
with open('./data/words.txt') as f_in:
print(f_in.read()[:100])
파일 내용의 후반 내용 일부는 다음과 같다.
with open('./data/words.txt') as f_in:
print(f_in.read()[-100:])
새 파일 작성하기¶
새 파일을 생성하여 내용을 넣으려면 open 함수를 쓰기 모드(w-모드)를 이용하여 아래 형식으로 호출하면 된다.
파일변수 = open("경로명/파일이름", 'w')
주의: 기존에 동일한 이름의 파일이 존재하는 경우 해당 파일내용이 삭제됨에 주의해야 한다.
이렇게 생성된 파일에 내용을 추가하려면 write 메소드를 아래 형식으로 활용한다.
파일변수.write("추가내용")
정리하면 다음과 같다.
with open("경로명/파일이름", 'w') as 파일변수:
파일변수.write("추가내용")
예제¶
현재 디렉토리의 하위 디렉토리인 data에 words_no_vowels.txt 라는 파일을 생성한 후에
words.txt 파일에 포함된 단어 중에서 모음을 전혀 포함하지 않는 단어들만 저장하고자 한다.
먼저, 문자열에 모음이 사용되었는지 여부를 검사해야 한다.
이를 위해 아래 기능을 갖는 avoids 함수를 구현하여 이용한다.
- 두 개의 문자열 인자를 입력받는다.
- 첫째 인자로 입력된 문자열에 둘째 인자로 입력된 문자열에 포함된 어떤 문자도
포함되지 않았을 경우
True를 리턴한다.
def avoids(word, forbidden):
for letter in word:
if letter in forbidden:
return False
return True
이제 avoids 함수를 이용하여 words.txt 파일에 포함된 단어들 중에서
모음(a, e, i, o, u)을 포함하지 않는 단어들만 words_no_vowels.txt 파일에 저장한다.
# words.txt 파일을 읽기 전용으로 열기
f_in = open('./data/words.txt')
# words_no_vowels.txt 파일 생성 (쓰기 기능 포함)
f_out = open('./data/words_no_vowels.txt', 'w')
# words.txt에 포함된 각 단어들 검사
for line in f_in:
if avoids(line, 'aeiou'): # 모음 포함 여부 판단
f_out.write(line)
else:
continue
# 파일 내용 추가가 완료되면 닫아 주어야 한다.
f_in.close()
f_out.close()
with ... as ...를 이용하여 여러 개의 파일을 아래와 같이 열 수 있다.
with open('./data/words.txt') as f_in, open('./data/words_no_vowels.txt', 'w') as f_out:
for line in f_in:
if avoids(line, 'aeiou'):
f_out.write(line)
else:
continue
열어야 하는 파일이 많으면 다음과 같이 열 파일들을 줄바꿈을 이용하여 구분하는 게 좋다.
with open('./data/words.txt') as f_in, \
open('./data/words_no_vowels.txt', 'w') as f_out:
for line in f_in:
if avoids(line, 'aeiou'):
f_out.write(line)
else:
continue
이제 모음을 포함하지 않은 단어들의 개수를 알아내기 위해
words_no_vowels.txt 파일에 문자열을 추가할 때마다 카운트하는 기능을 추가하자.
with open('./data/words.txt') as f_in, \
open('./data/words_no_vowels.txt', 'w') as f_out:
count = 0
for line in f_in:
if avoids(line, 'aeiou'):
f_out.write(line)
count += 1
else:
continue
print(f"모음을 포함하지 않는 문자열은 총 {count} 개 이다.")
기존 파일에 내용 추가하기¶
기존에 존재하는 파일에 내용을 추가하고자 할 때는 추가하기 모드(a-모드)로 파일을 열어야 한다.
with open('./data/words_no_vowels.txt', 'a') as f_add:
f_add.write("한줄 추가하기\n")
f_add.write("한줄 더 추가하기\n")
이제 words_no_vowels.txt에 마지막 5줄을 확인하면 다음과 같이,
앞서 추가한 두 줄이 파일 끝에 추가되었음을 확인할 수 있다.
with open('./data/words_no_vowels.txt') as f_in:
print(f_in.readlines()[-5:])
파일명과 경로¶
파일들은 디렉터리(폴더”라고도 부름) 안에 저장된다.
또한 실행중인 모든 프로그램은 현재 작업 디렉토리, 즉, 해당 프로그램이 실행되고 있는 디렉토리를 기억한다.
현재 작업 디렉토리 학인¶
현재 작업 디렉토리의 위치에 대한 정보를 확인하려면 아래와 같이 한다.
os: 운영체제(operating system)의 줄임말cwd: 현재 작업 디렉토리(current working directory)의 줄임말
import os
cwd = os.getcwd()
print(cwd)
즉, 파이썬이 현재 바로 위에 언급된 디렉토리를 기준으로 작업한다.
절대경로와 상대경로¶
cwd처럼 파일이 저장된 디렉토리의 위치를 알려주는 정보를 경로(path)라고 부른다.
경로를 설정하는 기준이 두 가지 있다.
- 상대경로: 현재 작업 디렉토리를 기준으로 파일과 디렉토리의 위치 결정
- 예제: 앞서 사용한
./data/words.txt는 현재 작업토리를 기준으로 하여 정해진 상대경로이다. 즉, 현재 작업 디렉토리에 포함된data라는 디렉토리 안에 있는words.txt를 가리킨다. - 점(
.)은 현재 작업 디렉토리를 가리킨다. - 점 두개(
..)의 현재 작업 디렉토리의 한 단계 상위 디렉토리를 가리킨다.
- 예제: 앞서 사용한
- 절대경로: 사용하는 운영체제 파일 시스템 상에서 최상단 디렉토리를
기준으로 파일과 디렉토리의 위치 결정
- 예제:
getcwd함수의 리턴값은 상대경로이다.- 윈도우의 경우:
C:\tf\GitHub\ProgInPython\notebooks\data\words.txt - 맥 또는 리눅스 경우:
/tf/GitHub/ProgInPython/notebooks/data/words.txt
- 윈도우의 경우:
- 예제:
주의: 윈도우 운영체제에서 역슬래시('\')는 원화기호('₩')로 표시됨.
os.path.abspath: 특정 파일의 절대경로를 찾기 위해 사용
os.path.abspath('./data/words.txt')
os.path.exists: 특정 파일 또는 디렉토리의 존재여부 확인- 절대경로 또는 상대경로 이용
os.path.exists('words.txt')
os.path.exists('./data/words.txt')
os.path.exists('/tf/GitHub/ProgInPython/notebooks/data/words.txt')
os.path.isdir: 디렉토리 존재 확인- 절대경로 또는 상대경로 이용
os.path.isdir('music')
os.path.isdir('./data')
os.path.isdir('/tf/GitHub/ProgInPython/notebooks/data')
os.path.isfile: 파일 존재 확인
os.path.isfile('./data/words.txt')
os.path.isfile('/tf/GitHub/ProgInPython/notebooks/data/words.txt')
os.listdir: 지정된 디렉토리에 포함된 파일 및 하위 디렉토리의 리스트를 리턴함
os.listdir(cwd)
예제: 디렉토리 탐색¶
지정된 디렉터리와 모든 하위 디렉토리를 "탐색(walk)"하여 모든 파일들의 이름을 인쇄하는 함수를 다음과 같이 재귀함수로 구현할 수 있다. 재귀함수에 대한 설명은 기본 자료형: 함수를 참조한다.
os.path.join: 디렉토리 경로와 파일 이름을 받아서 온전한 경로로 결합한다.
def walk(dirname):
for name in os.listdir(dirname):
path = os.path.join(dirname, name)
if os.path.isfile(path):
print(path)
else:
walk(path) # 재귀 호출
현재 작업 디렉토리를 기준으로
walk 함수를 실행한 결과는 다음과 같다.
주의: 사용하는 컴퓨터마다 실행결과가 다를 수 있다.
walk('.')
예제¶
os 모듈에 walk라는 함수가 이미 정의되어 있으며, 앞서 정의된 walk 함수보다
많은 정보를 제공한다.
예를 들어, 아래 함수 walk2는 walk와 동일한 일을 한다.
대신에 os.walk 함수를 활용하였다.
for item in os.walk('./codes'):
print(item,'\n')
def walk2(dirname):
for root, dirs, files in os.walk(dirname): # 현재 디렉토리, 하위 디렉토리 리스트, 폴더 리스느
for filename in files:
print(os.path.join(root, filename))
walk2('./data')
예외 처리¶
파일을 읽거나 작성하려고 할 때 종종 오류가 발생한다.
'FileNotFoundError': 존재하지 않은 파일을 읽으려 할 때 발생
PermissionError: 접근 또는 수정 권한이 없는 파일을 다루고자 할 때 발생IsADirectoryError: 디렉토리를 열려고 할 때
이렇게 오류가 많이 발생할 수 있다는 점에 대해 대비하는 것이 필요하다.
예를 들어, try ... except ... 명령문을 이용할 수 있으며,
if ... else ... 명령문과 유사하게 실행된다.
try구절을 먼저 실행한다.- 문제가 없다면 except 구절을 건너뛴다.
- 만약 오류가 발생하면, except 구절을 실행한다.
보다 자세한 설명은 프로그래밍 기본 요소: 오류 및 예외 처리를 참조하라.
예제¶
아래 코드는 존재하지 않은 파일을 열 때 오류가 발생할 것을 대비한 코드이다.
try:
fin = open('bad_file')
for line in fin:
print(line)
fin.close()
except:
print("파일을 열고자 할 때 문제가 있습니다.")
물론 아래도 가능하다.
try:
with open('bad_file') as f_in:
for line in f_in:
print(line)
except:
print("파일을 열고자 할 때 문제가 있습니다.")
예제: 파일 저장하기¶
아래 내용을 dialogues.txt 파일에 저장하라.
Man: Is this the right room for an argument?
Other Man: I've told you once.
Man: No you haven't!
Other Man: Yes I have.
Man: When?
Other Man: Just now.
Man: No you didn't!
Other Man: Yes I did!
Man: You didn't!
Other Man: I'm telling you, I did!
Man: Oh look, this isn't an argument!
(pause)
Other Man: Yes it is!
Man: No it isn't!
(pause)
Man: It's just contradiction!
Other Man: No it isn't!
Man: It IS!
Other Man: It is NOT!
Man: (exasperated) Oh, this is futile!!
(pause)
Other Man: No it isn't!
Man: Yes it is!이제 dialogues.txt 파일을 불러 들여서 각 역할 별 대사를 리스트로 저장하는 코드는 다음과 같다.
def role_words(file_name, role):
words = []
try:
with open(file_name) as data:
for each_line in data:
try:
line = each_line.split(':', 1)
line_spoken = line[1].strip()
if line[0] == role :
words.append(line_spoken)
except IndexError:
pass
return words
except IOError as err:
print('File Error: ' + str(err))
role_words("data/dialogues.txt", "Man")
role_words("data/dialogues.txt", "Other Man")
연습문제¶
words.txt파일에 저장된 단어들 중에서 줄바꾸기 문자를 제외한 문자열의 길이가 20 이상인 단어들만 출력하는 프로그램을 작성하라.
- 아래 기능을 수행하는 함수
has_no_e라는 함수를 구현하라.- 하나의 문자열을 인자로 입력받는다.
- 인자로 입력된 영어 문자열에 알파벳
e가 포함되지 않았을 경우True를 리턴한다.
words.txt파일에 포함된 단어들 중에서 알파벳e를 포함하지 않은 단어만 출력하는 프로그램을 작성하라.
- 아래 기능을 수행하는 함수
- 본문에서 구현한
avoids함수를 이용하여 다음 기능을 수행하는 프로그램을 구현하라.- 사용자로부터
input함수를 이용하여 영어 알파벳 문자열을 입력받는다. words.txt파일에 포함된 단어들 중에서 사용자가 입력한 문자열에 포함된 어떠한 알파벳도 사용하지 않는 문자열의 개수를 출력한다.
- 사용자로부터
- 앞 문제에서 구현한 프로그램이 가장 적은 수의 단어를 배척하도록 하는 문자열을 찾아라.
단, 길이가 5이어야 한다.
- 본문에서 구현한
- 아래 기능을 수행하는 함수
uses_only함수를 구현하라.- 두 개의 문자열 인자를 입력받는다.
- 첫째 인자로 입력된 문자열이 둘째 인자로 입력된 문자열에 포함된 문자만으로
구성되었을 경우
True를 리턴한다.
words.txt파일에서acefhlo에 포함된 문자들만 사용하는 단어를 출력하는 프로그램을 구현하라.
- 아래 기능을 수행하는 함수
- 아래 기능을 수행하는 함수
uses_all함수를 구현하라.- 두 개의 문자열 인자를 입력받는다.
- 첫째 인자로 입력된 문자열이 둘째 인자로 입력된 문자열에 포함된 모든 문자가
최소 한 번 이상 포함되었을 경우
True를 리턴한다.
words.txt파일에 포함된 단어에서aeiou에 포함된 모음을 모두 사용한 단어의 개수는?words.txt파일에 포함된 단어에서aeiouy에 포함된 알파벳을 모두 사용한 단어의 개수는?
- 아래 기능을 수행하는 함수
- 아래 조건을 만족하는
sed함수를 구현하라.- 4개의 인자를 받는다.
- 첫째 인자: 문자열
- 둘째 인자: 문자열
- 셋째 인자: 파일 이름
- 넷째 인자: 파일 이름
- 첫째 파일의 내용 전체를 둘째 파일로 옮긴다.
- 단, 첫째 인자로 입력된 문자열은 모두 둘째 인자로 입력된 문자열로 대체되어야 한다.
- 파일을 열거나, 읽거나, 쓰거나, 닫을 때 오류가 발생하는 경우을 대비해서
예외 처리를 사용한다.
견본답안: http://greenteapress.com/thinkpython2/code/sed.py
- 4개의 인자를 받는다.
- 아래 문장들을
sketch1.txt파일에 저장한다.Man: Is this the right room for an argument? Other Man: Oh I'm sorry: or the full half hour? (pause) Man: Ah! Just the five minutes.sketch1.txt파일에 저장된 문장들을 읽어 들인 후 아래 처럼 출력하는 함수role_words를 구현하라.
##### 힌트Man said: Is this the right room for an argument? Other Man said: Oh I'm sorry: or the full half hour? Man said: Ah! Just the five minutes.- 파일을 읽어 들이기 위해 open 함수 이용
- split 메소드 활용. 단, split 메소드 옵션에 주의한다.
(두 번째 줄 문장에 콜론(
':') 기호가 두 번 들어가 있음에 주의한다. 옵션을 1로 주어야 한다.) - 셋째 줄은 ":" 기호를 갖지 않음에 주의한다.
따라서
split(':')이 이 경우 에러를 발생시킨다. 이 경우를 대비해서try ..., except ...를 활용할 수 있다.
- 앞서 예제에서 다룬
role_words함수를 수정하여 각 역할별 대사를 각각dialogues_Man.txt와dialogues_Other.txt파일에 저장하는 함수인role_texts함수를 구현하라.